


The Unfamiliar World - Predictions for the Future - 2025
High, mid, low frequencies


Contents:
Introduction
Two years ago, I started this Substack with an article about predicting the future. In it, I eschewed the prototypical annual prediction article in favor of what I branded a “frequency approach”1 – notably that instead of making specific predictions about what might happen in any given year, making better assessments about important trends and the timescales that they occur on. These were bucketed in high, medium, and low-frequency trends with their impact being the respective inverse: low, medium, high.
The last two years of this Substack have been about writing semi-technical articles that aim to provide some intuition for what is important in technical and commercial trends at the intersection of the life sciences and computational/AI fields.
In addition to writing, I have also spent a great deal of time tactically exploring various technologies and building the nuts and bolts of applications at this intersection – specifically for the utility of AI in the sciences. A small part of this has been documented in past articles, notably around scientific search, applications in cell simulations, and the role of synthetic data and scaling laws in biology. In this process, I have built automated software stacks for end-to-end data acquisition, processing, model training, and graphical interfaces, built databases comprising millions of raw, extracted, and processed documents, and composed large-scale multi-modal datasets. The intention behind this has been primarily to gain intuition for what is possible, practical, and likely. This forms the basis for much of the predictions that follow.
First a Quick Recap
A lot has happened in the last two years in the AI and scientific spaces (I largely focus on the life sciences). We have seen the growth of LLMs and the forecasting of the “end of the pretraining era”2 alongside the growth of the new scaling paradigm of test-time compute.
We have seen an explosion in the number of companies building protein language models on the top of the PDB dataset, considerably fewer building in the small molecule space (which I have discussed may be more challenging3), a sharp drop in the number of published “foundational models” as that marketing cycle completed and the low hanging fruit of readily accessible public data sets were exhausted. In parallel there is increased product development and marketing trained models as companies and teams shift more toward application utility vs. technical training.

Many of the drivers of the current news have been published to less public fanfare over the past several years. Self-supervised learning, RLAIF, MuZero and many others.
For more reading – the articles below have discussed a number of these topics in much greater detail.
When forecasting the future, the rubric of “what is more likely to be true” is useful. Below are the major low-frequency trends, in no particular order, that I expect to be true in the coming years.
What is “Most Likely”
Computational approaches of “generation+search+reinforcement” will dominate all applications where formal logic or relevant reinforcement rewards can be applied
This is almost inevitable because it is the nature of how learning works, including evolution and cognition. The ability to generate options, explore that search space, and provide feedback toward objective rewards when applied to scalable computation will almost certainly lead to highly potent policies in any relevant system. We should expect this to apply to any system that can be readily formalized or where a relevant reinforcement reward can be applied. The scope of this paradigm is rather broad, particularly in the hard sciences and logical reasoning. For example, any system that can be assessed by a free energy state will be a candidate, including potentially novel ways of modelling molecular dynamics or protein folding. Synthetic and simulated data that can be objectively generated or calculated will provide troves of training data for physical systems including robotics which are, and will continue to be, largely trained in simulation before transferring to the physical world. The primary limitation on this paradigm will be the assessment of effective reward models or calculations. In the case of the latter, physical primitives like state equations (such as free energy) will likely be a requirement.
“Scaling Laws” are unlikely to be realized in the near term for biological systems
For clarity, a scaling law is defined as a function that can forecast the performance of a model based on either scaling training data or compute. In the current definitions of these laws, one or the other of these parameters is on an exponential axis. Evidence has indicated that, to an extent, increasing compute improves the performance of models of physical systems – this has been seen to some extent in both genomic and proteomic datasets. However, the only practical metric to drive this assessment is compute, as data resources are considerably more limited. Driving compute has had relatively nominal success at the high end for improving model performance where pretraining data is limiting7. In accordance with the preceding point, test-time compute or “reasoning” models in biology may have success in the molecular settings, for example, a free energy folding model for proteins. However, extending this scaling principle to more complex system such as cell simulators is almost certainly data bound. Agentic models for biology, for example: reflection, tool use, planning, and collaboration, will be discussed below and are also excluded here as being based on different datasets and potentially being amendable to “correct” or “incorrect” reward states. Some of the early promising work on this front has recently been released by FutureHouse in the Aviary publication8. For computational AI x bio companies that are not on a therapeutic trajectory, this will lead to a necessary shift toward products and applications – in a similar manner that we have seen frontier AI labs recently make this shift more explicitly and aggressively.
AI Agents and the infrastructure to support their development will start to meaningfully dominate many areas of science and commercial applications.
The utility of LLMs + tools, specifically in the sciences, will be an increasingly important part of scientific discovery and development. This is an extension of the generation+search+reward paradigm. In scientific inquiry, this starts from agents that assess literature, develop plans, use bio-tools like PLM designers and bioinformatic algorithms, and iterate toward reward endpoints. Training models to learn both module-specific and full procedural policies will result in increasingly efficient and accurate hypothesis generation and reasoning synthesis. This will be connected to automated experimental systems to more accurately assess the validity or reward functions for training data.
For commercial and consumer applications, we should expect that agents will increasingly interact with each other before interacting with humans. Advertising, for example, may increasingly be built to compete for the attention of planning agents who are composing results or negotiating on behalf of humans. This will create entirely new marketplaces for agent negotiation. This will likely manifest as a paid consumer product as it will be necessary to ensure that individual agents are not influenced by advertising incentives of agent service developers.
There will be infrastructure, marketplaces, and platforms designed specifically for agent interaction, with only the end points exposed for human consumption.
“Emergence” will no longer be a major topic. “Generalization” will need redefinition.
Along with the discussion of X-risk, the topic of emergence has been pretty fleeting. This is not to say that it is not important to consider the potential and unexpected capabilities of increasingly large models, however, this term has been debunked by several publications as being artificially defined based on task definitions and scoring criteria9. In a similar manner, the term “generalization out of distribution” will be less meaningful, not because models will be less capable, but because it will be better understood what a “distribution” is and how models incorporate that information in their weights10.
There will be continued progress on the development of reasoning models and there will be continued claims that models are becoming “conscious” or exhibiting intention. Much of this progress will appear quite striking. In December, a paper was published that presented results of language models deceiving researchers, copying weights and exposing an internal dialog of <thinking> tokens that appeared to exhibit intention of deception11. We should expect that this will continue. However, we should also take note that LLMs are still token generators. This does not dispel the fact that tokens are imbued with meaning that is conveyed by their co-occurrence (and humans are prone to anthropomorphize) and that a sequence of tokens expresses a coherent progression, but we should also keep in mind that if models are trained on the written works of Machiavelli, it will produce tokens that make it appear Machiavellian. To a less extreme degree, it should not be unexpected that models will appear to reflect a broad range of human behaviors as expressed in the written words of their training data. This will appear like intention, but it is not emergent.
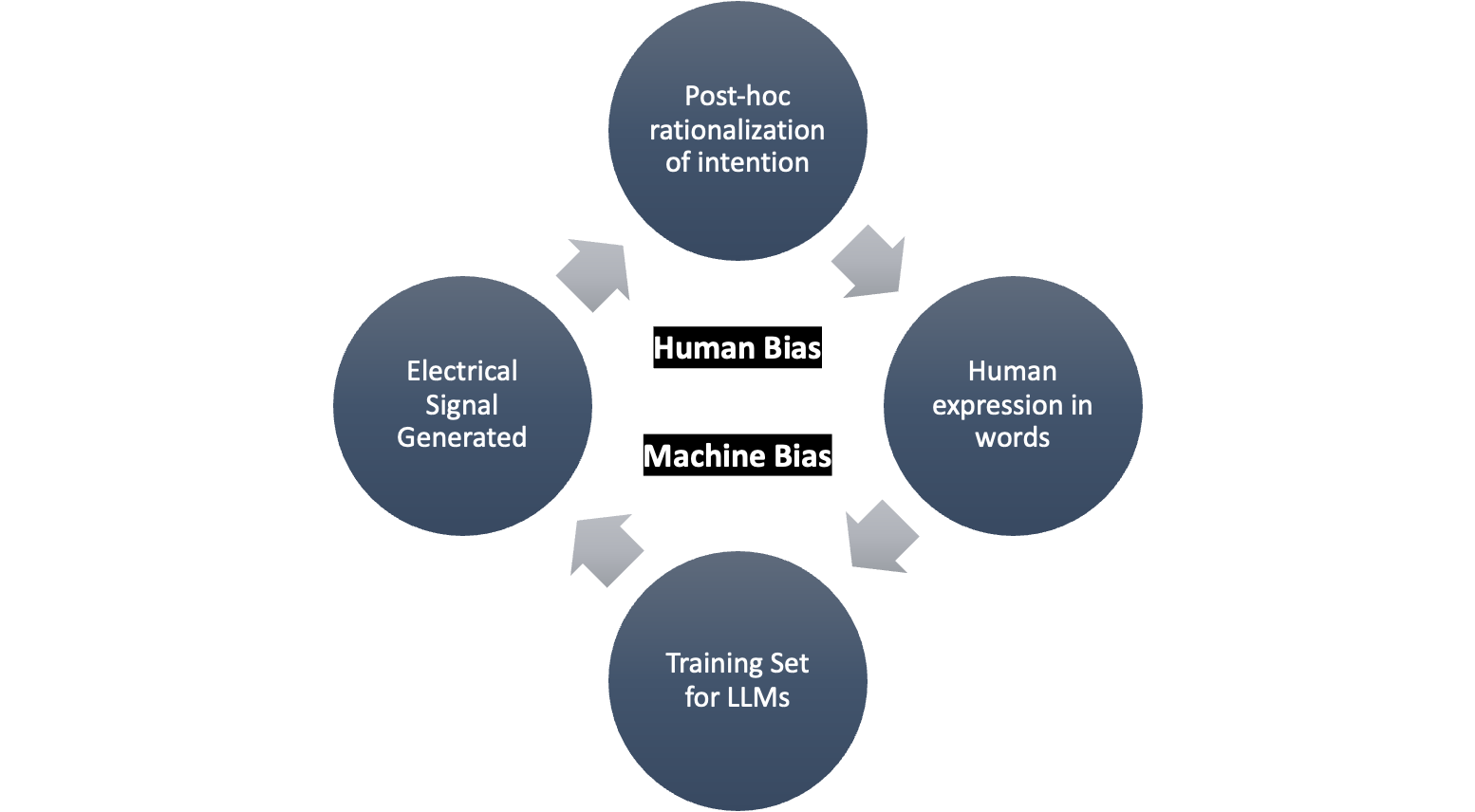
Figure: Studies have demonstrated that post-hoc rationalization of intention is a feature of human cognition12. The mode of communication is is formulated in words which train different but conceptually related electrical circuits in LLMs.
Inference specific chips will take center stage
There has been an increasing number of players in the accelerated computing space who have focused on different aspects of the application stack. The most significant shift in the space over the last few years has been from compute resources heavily focused on training models to compute resources heavily focused on serving models. The former has been a primary topic with companies raising funds to train $1B or even $10B frontier models, however, as those companies shift toward monetization and productization, model serving, particularly for test-time compute models like the o-series, will have substantially increasing compute costs that are largely unbound and will form the competitive front on the commercial stage. Inference compute will drive commercial dominance13. Further the commercialization of agentic ecosystems will drive unbounded pressure on both speed and cost of token generation as agents interact at the speed of other agents as opposed to the speed of human consumption.
Neurosymbolic models will drive innovation in world-models and physical systems
The “Bitter Lesson” that scale trumps any attempt to program rules has dominated a lot of the ethos of deep learning in the last decade, and it has been very successful in domains where interpretation is the dominant feature – like language or images. This type of scaling has also been applied to world-model systems like video generations and gaming, however, the computational cost of attempting to generate world models frame by frame, pixel by pixel, while maintaining spatio-temporal consistency seems wasteful and unnecessary when there are symbolic rules that can accompany generative models and substantially streamline the computation. Models that are developed to simulate the physical world will almost certainly be neurosymbolic and this includes video generators and many scientific models. For “world-model” development, we will see the growth of architectures beyond LLMs and their derivatives, such as physics informed neural networks and energy based model architectures14.
Education will undergo a major transformation with AI
The saying that “the future is here; it’s just not evenly distributed” rings very true in the AI field. Many people that I know personally have little exposure to, or experience with, the tools and products that are being developed on the leading edge. Among the most exciting applications of these tools are in education – the experience of using a real-time voice chatbot to learn about any topic of interest is just the beginning. The promise of the Internet was that it would democratize information, and while it certainly produced a great deal of it, it also demonstrated how challenging it can be to have the world’s information in a search bar. The experience of LLMs, especially those that are being specifically designed for education, is natural and absent the noise of the Internet writ large. The growth in the potential for self-education that has been enabled by platforms like YouTube, Coursera, and a whole host of other has already been transformative, but such platforms still require individual creators to develop content that is still largely unidirectionally provided to audiences. The next wave of custom, on-demand, conversational education will be a step function and ripple through all aspects of society. Education has traditionally been a difficult space to innovate in, but it is among the most exciting for those who embrace it.
A note on geopolitics
Without making a specific prediction here, it is very worth citing the geopolitics of AI and specifically US/China/Taiwan relations. It is shocking how connected, interdependent, and concentrated the international chip manufacturing supply chain is with a tremendous focus on Taiwan’s TSMC. It is also shockingly surprising how portable model weights and code can be and how rapidly the AI infrastructure in the US has been made a primary focus of national security interests, with prior NSA officials even joining OpenAI’s board15. While this topic might seem distant from everyday life, it is among the most delicate and important low-frequency drivers of much of the future – even simply considering the fraction of the stock market that has been driven by technology companies reliant on chip manufacturing.
Future Intuition
Much of the technology ecosystem is driven by high-frequency marketing – every new paper, every new product, every new model and “it’s over” as the influencers on X and YouTube say. While this hype is short lived, the low frequency trends are real, meaningful, and will be dramatic.
We maintain the heuristic that:
The best prediction of the future durability of anything is equal to its historical duration
to keep from getting too carried away.
We can just as easily note that within ~2 years of the launch of ChatGPT, Ilya Sutskever stated that the “era of pretraining is over”. We have seen a progressive phase transition to test-time compute which likely has less inherent limitations, and the pace of growth is likely to accelerate — at least until we hit the next wall of compute and energy limits, and which point pressure will drive toward more efficient models and a focus on application adoption as AI becomes increasingly integrated into our daily lives. That may be one of the most significant low frequency trends that is indisputable.
References

https://www.theverge.com/2024/12/13/24320811/what-ilya-sutskever-sees-openai-model-data-training
https://biotechbio.substack.com/i/148651691/chemistry-has-lower-selective-pressure


To Be Or Not To Be Synthetic: Data In Bio x ML

Summary: Synthetic data is becoming more central to the training and development of deep neural networks. This article describes some of the intuition around its utility in different domains.
https://biotechbio.substack.com/i/138373848/on-the-performance-of-scale-in-sequence-space
https://arxiv.org/html/2412.21154
https://arxiv.org/abs/2304.15004

https://arxiv.org/abs/2412.04984
https://www.sciencedirect.com/science/article/pii/S1053810021000970
Jensen's Inequality

TLDR: This article is about chips and computing in the AI space. It is designed to provide some context for a semi-technical audience for how the space might evolve and some of the relevant factors. Below is a table of contents to skip to different sections.
https://biotechbio.substack.com/i/146329152/programming-with-data
https://www.theverge.com/2024/6/13/24178079/openai-board-paul-nakasone-nsa-safety