


The Crazy Week at OpenAI
The last week has been a tumult of news in the AI world - with the unexpected ouster of CEO Sam Altman from OpenAI, the pending implosion of its employee base, and the presumptive return to order with a revised board of directors and possibly corporate structure. It’s been a drama unfolding on X that has been unparalleled in recent Silicon Valley history.
There remain many questions as to the rationale of the sudden firing and there have been no definitive answers but as time progresses, leaks begin to appear that hint at an internal concern over a new AI advancement that some insiders feared could be dangerous — and that perhaps Altman was not upfront with the Board about progress on this front.
This is just an interpretation, however, the implications are worth considering. What has risen to the top is an internal memo referring to a project called Q* which may relate to advances in logical reasoning including mathematics.
Mathematics has long been considered a holy grail of AGI as an achievement that epitomizes an understanding of reality. Similarly, the achievement of an “AI-Scientist” — one that could make hypotheses about the world and then conduct experiments to generate new knowledge — would be a monumental advancement of a similar nature. This latter has been the mission of the recent announcement of yet another AI nonprofit in SF, Future House1, backed back Eric Schmidt to develop AI-Scientists.
This article provides some intuition for how AI mathematicians might be developed (and what Q* might refer to). It is an outsider’s perspective so that’s worth keeping in mind.
Proving Math Step by Step
The phrase step by step has become canonical in the LLM reasoning world as a prompt preface that dramatically improves the quality of an LLM’s rational output. In the context of mathematical theorems, the impact is no less.
In order to build a framework for automating robust mathematical proof generation several logical and semantic frameworks have been developed. One such example is Metamath2. Briefly:
Metamath is a simple and flexible computer-processable language that supports rigorously verifying, archiving, and presenting mathematical proofs. Metamath has a small specification that enables you to state a collection of axioms (assumptions), theorems, and proofs (aka a "database"). We have databases for several axiomatic systems. Metamath provides precision, certainty, and the elimination of human error. Through Metamath you can see mathematics developed in complete detail from first principles, with absolute rigor, in a way unlike any other system.
The basics of Metamath begin with a few axiomatic statements and then proofs proceed step by step via single variable substitutions. As such every step of the proof is directly tied to the previous step via a unique substitution of a variable with a statement or axiom that has previously been constructed in the thread. This is not dissimilar from the method of Godel numbering3 that was used to demonstrate the famous Incompleteness Theorem and creates a fully connected and robust proof thread.
In form factor, Metamath proofs look like the below. The specific syntax isn’t critical for this discussion, but the visual may be useful as the database of Metamath syntax will later serve as a training set for an LLM.

4
Metamath has ~23,000 proofs of this structure in its database.
Generating New Proofs
In 2019/2020, OpenAI published the below article:

From the abstract:
We explore the application of transformer-based language models to automated theorem proving. This work is motivated by the possibility that a major limitation of automated theorem provers compared to humans – the generation of original mathematical terms – might be addressable via generation from language models. We present an automated prover and proof assistant, GPT-f, for the Metamath formalization language, and analyze its performance. GPT-f found new short proofs that were accepted into the main Metamath library, which is to our knowledge, the first time a deep learning based system has contributed proofs that were adopted by a formal mathematics community5
At a high level, an LLM was trained on the Metamath dataset in a decoder only model and was coupled to a verifier that checked to ensure that outputs were consistent with Metamath grammar. To demonstrate proof, a proof tree and a queue of open sub-proofs was maintained to be expanded in succession. The net result of this paper was that the model was able to identify 23 shorter proofs than existed in the existing Metamath database. The conclusion was that LLMs combined with a formal mathematical framework can be used to construct proofs.
Logical Reasoning 2.0 — Let’s Verify Step by Step
Earlier this year, OpenAI published a paper titled Let’s Verify Step by Step

The goals of the paper were to present an improved method of confirming logical reasoning by LLMs. It presented two basic frameworks for Reinforcement Learning — an Outcomes based one and a Process based one — the former evaluating the final output for correctness and the latter evaluating each step. One of key takeaways from the paper relates to how much training and compute is necessary to improve logical reasoning. The most interesting key approach here is that the authors did not perform reinforcement training on the LLM itself. Instead, for each iteration of logical progression, the LLM would generate many possible outputs, and the reinforcement training was on a policy discriminator for the most correct solution to move to the next step of logical progression. A key aspect of this approach is that the LLM generator itself was not a bottleneck of training scale, and the discriminator for choosing the most correct answer was the centerpiece of reinforcement learning. This may lead to tremendous advances in both the scalability of these models as well as an escape from the limitations of the requirement for human generated data to train the generator LLM. Such models may continue to improve based on generated synthetic outputs instead of human inputs. This sets up the potential for recursive self improvement.
Q-Learning + A* = Q*
This is some conjecture but the basic rationale makes sense. Training a policy discriminator to select the most correct answer from an array of generated answers produced by an LLM is an example of a model free reinforcement learning task. In the context of, for example, proof generation, logical reasoning, and hypothesis exploration, one may want such to explore off-policy results to expand the search space which is referred to as Q-learning7. The supposition of the * relates to a search optimization algorithm called A*8 which is a way of determining the optimal path through a graph using both knowledge of the network as well as an overall heuristic. Such an example would be if you were traversing a city block by block and you knew the general direction of your destination, you would incorporate both current information about the streets along with the general direction of your destination when considering what actions to take at any intersection. The “Q” in Q-learning refers a Quality function under a given state and action set. Learning to optimize this quality may be akin optimizing the heuristic in an A* search. This latter analogy may not be necessary as A* is a rather old algorithm, however the general idea may be similar. For example, if one wished to navigate a possible theorem proof tree, one might know which options are available at any given juncture (assuming the proof follows a single substitution model at each step) and would want to determine a heuristic for which path moved a proof closer to a specified target.
In essence this would be a marrying of the generative capabilities of LLMs with the model free reinforcement learning algorithms that power policy search models like MuZero9 or AlphaZero10. Being able to both generate and search recursively at scale is a powerful combination.
It doesn’t require that an LLM be super accurate, only that it might generate at least one useful output that could then be selected by a reinforcement model to provide the next most correct logical step.
What Does This Mean?
Looking at this from an outside perspective, the following synthesis make some sense:
The idea of using LLMs that are fixed in size to generate a large number of possible outputs based on potentially limited training data (for example Metamath data), and then training a discriminator using reinforcement learning to optimize the high “quality” outputs as a heuristic to add to an overall search space towards a specific conclusion ultimately leads to the potential to generate novel logic. Perhaps more importantly it does so in a way that could be largely scaled independently of human contributed data. One implication of this is described in this paper11 by Andy Jones as the train/test time compute trade-off, or more generally that, if your inference involves a search function, at a fixed computing budget between training and inference, you can train on smaller datasets but use large search space during inference to maintain overall performance. This increases the compute during inference while decreasing compute during training. In some contexts, this has been considered as a LLM “pondering” or contemplating and might be akin to System 2 type thinking that is important for reasoning. This type of tradeoff has been used in a number of games such as the Libratus poker model12
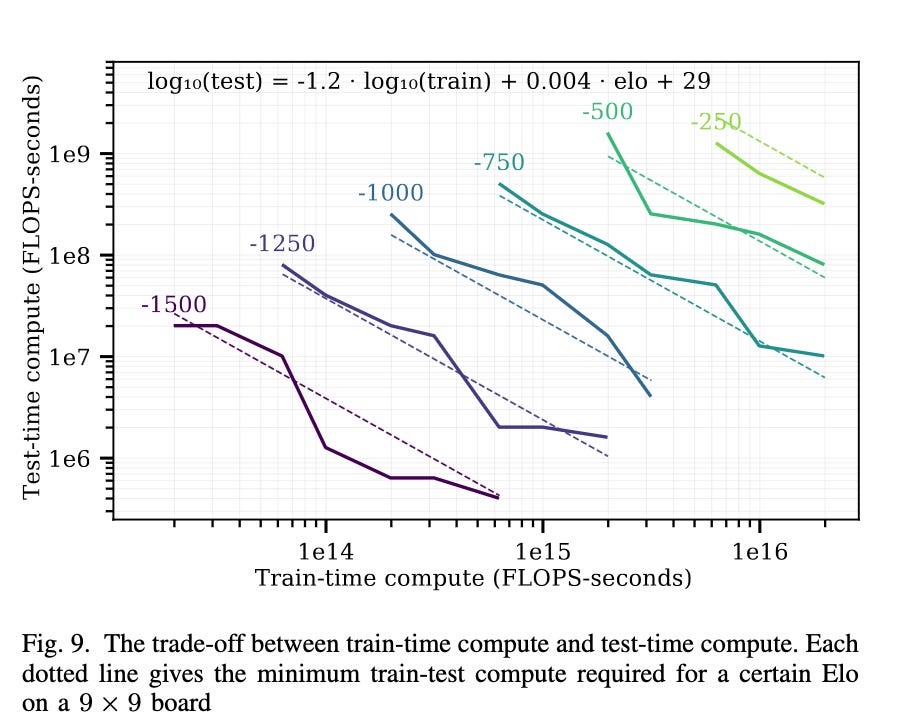
This graphic is showing that training compute and testing compute are inversely related at a fixed model performance. In a fixed context, if you are willing to wait 10 times as long for answer, you might be able to work with 10 times less original training time/data (this isn’t a precise comparison but it’s illustrative). This, of course, isn’t appropriate for chatbots, but it may be appropriate for solving complex logic problems in science, math, and strategic planning.
It is likely that such approaches will also result in a fair amount of nonsense, as any break in a logical chain can derail the overall conclusion, however, from an alignment standpoint, a process based optimization where logical steps are delineated might actually provide better transparency into these logical gaps.
One might consider this a step toward mathematical or scientific co-pilots similar to how such models have been used for code generation in programming
Agents, Limitations, and the Future of Science
It’s important to keep in mind that none of this indicates that AI system will be attaining their own agency in setting their own existential goals. The overall objectives still firmly remain in the hands of humans. However, it does mean that such systems, once pointed in a direction, may be able to extremely rapidly generate new concepts, set and achieve sub-goals, and rapidly self improve. There are rightly concerns about this as such systems scale. Though I have not found independent verification — the following was posted this last week:

It’s also worth pointing out that while such systems can possibly generate new hypotheses or new content - they do not strictly generate new knowledge. In logical systems that are strictly formal such as math, these may be equivalent (provided that hypotheses are grammatically correct as with the Metamath verifier above), in most other domains of knowledge, notably in the biological sciences, they are not. This does not preclude connecting such models to robotics to preform experiments, and this is likely the path forward for science. Indeed this has already been done14 and has been discussed by academic leaders in the space such as Larisa Soldatova15 and is the subject of yet another AI non-profit led by a Sam16
On a Concluding Note
As I have written in the past, the opacity and hyperbole around these types of capabilities are often not healthy for the public narrative, though it will likely continue. These articles are an effort to provide some general intuition into the underlying ideas, without over extending the reach. It is important to recognize, however, that the pace of development in both software and hardware alongside the tremendous amounts of money and talent density being directed at this field is uniquely exceptional and will almost certainly result in large scale changes to the world over time.
References
https://www.msn.com/en-us/money/other/former-google-ceo-eric-schmidt-bets-ai-will-shake-up-scientific-research/ar-AA1jcZFQ
https://us.metamath.org/index.html
https://en.wikipedia.org/wiki/G%C3%B6del_numbering
https://us.metamath.org/mpeuni/3bitr2ri.html
https://arxiv.org/abs/2009.03393
https://arxiv.org/pdf/2305.20050.pdf
https://en.wikipedia.org/wiki/Q-learning
https://en.wikipedia.org/wiki/A*_search_algorithm
https://www.nature.com/articles/s41586-020-03051-4
https://arxiv.org/abs/1712.01815
https://arxiv.org/pdf/2104.03113.pdf
https://x.com/polynoamial/status/1676971506969219072?s=20
https://www.linkedin.com/posts/colly_google-now-spends-more-money-on-compute-than-activity-7134090193967415296-ssjh?utm_source=share&utm_medium=member_desktop
https://www.science.org/doi/10.1126/science.1165620
https://www.linkedin.com/posts/jasonmsteiner_prof-larisa-soldatova-automating-science-activity-7122695401912041472-PQ85?utm_source=share&utm_medium=member_desktop
https://www.futurehouse.org/articles/announcing-future-house