
Intuition on AI Scale for Biologists
It's all about "informational impedance matching"


Scale is All You Need…Maybe
The news has been awash with mega funding rounds for AI companies. It is not uncommon to see 9 figure funding for startup and billion dollar partnerships are being struck with the leading companies like Anthropic and OpenAI.
Inflection AI has said they have/will be spending $1B on a compute cluster1.
GPT-4 or versions of Google Gemini have been cited to cost over $100M in training costs alone and have been reported to have over 1T parameters at the least2.
Dario Amodei has stated that it is well within expectation to be training models that are 10 or 100 times larger within the next few years.
In the life sciences, the company EvolutionaryScale, started by an ex-Meta team that built the ESM protein folding model have been reported to plan on spending (provided they can continue to raise capital) several hundred million dollars on compute costs over the next few years to test scaling laws in biology3.
Perhaps the biggest outstanding question is what will happen? How much better can things get and what are these dynamics?
The race is definitely on — from a VC perspective, it seems that the biggest bet is on who will actually be right on the value of scaling laws. Clearly Thrive Capital is betting on this paying out at an $80B valuation for OpenAI shares4.
In the churn of all of this — I began to wonder about the intuition behind these scaling laws — and some of the publications and papers that have spoken to this.
One of the motivating factors for the curiosity is the balance between data, model size, and compute notably as it applies to data in the life sciences.
I have written elsewhere about some of my thoughts/observations on the idea of emergence5 (which is perhaps more of a definitional argument than a technical one), and also about some of my thoughts on the concept of performance or SOTA in biological deep learning models6.
Recently a few additional reviews have been published about the rather mixed performance of some of the larger “foundational” models of single cell transcriptomics as compared to either other more simple models or even ground truth789.
The Race to Scale Reaches Bio
It’s clear that the performance of these models still has a long way to go. The open question is how much of this will be a consequence of scaling model size and how much is a data issue.
For some benchmarks
GPT-4 has been reported to have 1.8T parameters — to be fair, this is reported to be an 8 way mixture of models at ~220B parameters each, but it is large. If one follows Anthropic’s forecasting, models will be reaching the 10s to 100s of trillions of parameters in the near future10
One of the larger models in biology is the ESM-2 model by Meta, which (as published) had reached a top end size of 15B parameters11 . A second larger model, xTrimoPGLM has been published at 100B parameters for protein folding.12
One of the larger models from the private sector in RNA biology — the BigRNA model from Deep Genomics — is 1.8B parameters as a 7 way mixture model13
Single cell genomic/transcriptomic “foundation” models in the academic space rarely break a few 100Ms of parameters even at the top end14 15.
So, it is clear that most biological “foundation models” are at least 3, and in the near future closer to 5, orders of magnitude smaller than the models being trained on text, images/video/audio, etc.
How should we interpret this in light of the future of biological foundation models?
Is this a data problem? A resource problem? An industry/economic race problem?
For sure the life sciences do not historically have the winner take all dynamic that has existed in the tech industry and further, the role of data has played a much more significant role from a value perspective in biopharma than say, for example, content on the internet. As such, while there is a growing corpus of data in the public domain, the balance of private/public data that may be useful for training models is likely inverted in the life sciences compared to the technology sector. *This is not to say that private data in the tech sector is not abundant and valuable, just that it is not generally categorically different from a distributional perspective to the abundant data in the public domain for the purposes of training effective foundation models. This is inverted in biopharma, where a tremendous amount of diverse data that would be useful for training such models is likely siloed away in fragmented corporate data lakes. Further, it is not necessarily in the interests of any industry incumbent in the life science to actually build and commercialize foundational models (as least those trained on their proprietary data) as it is not their business model — which is explicitly focused on therapeutics. Some of the more forward thinking “techbio” companies like Recursion may move more in this direction if they choose to commercialize models based on their internal data, but this seems more a strategy to find monetization paths than a genuine commercial development approach.
However, I suspect that the single largest generational investment miss that people will make in the coming decades is continuing to believe that the primary value of investments in drug discovery is in the specific assets themselves. Currently the prevailing wisdom, supported by a stream of early techbio companies like Atomwise16, Benevolent, Exscientia, for example, turning to their own wholly owned assets seems to make this case, but this is near term consequence of early adopters, not the long term trend of AI.
Intuition of Scaling Laws
One of the most useful and intuitive ways that I have found to think about the role of model scale is a framework of “informational impedance matching”
From a visual perspective, I think of training data being “poured” into a deep neural network and “filling” it up in a sense. By filling it up I mean that the network ultimately retains a repository or a reflection of the nature of data it trained on within its weights. This is actually one of the most magical aspects of deep learning — the fact that it can actually retain knowledge that can then be updated, transmitted, and utilized in nearly instantaneous fashion. This is, by far, the most differentiating aspect of neural nets as compared to bioinformatics.
The idea of impedance matching then is a perspective of matching the informational content of the training data to the informational storage capacity of the network. The informational storage capacity of the network is a consequence of its architecture, of which parameter count is one of the primary hyperparameters.
One of the most valuable benefits of deep learning models is that the “informational content” of the training data does not need to be human prescribed. This is one of the key advances from older expert system type AIs to current approaches. Some examples of the “informational content” of training sets on the internet are:
The statistical co-occurrence of words and their relative positioning in sentences
The identification of observable features (e.g., edges, shapes, colors, etc) of image and their relative relationships and human assigned labels
The co-occurrence of image features with word structures — for example for text to image generators
This content is embodied within training data that is sufficiently diverse but does not need to be made explicit as it is fed into a neural network. It also follows a statistical distribution which the network gets exposure to — for example, the network may see many examples of language tokens representing “the” and “dog” many fewer representing “xyz”. As such any relationships between “the” and “dog” will likely have higher confidence and reliability scores than those between “dog” and “xyz”. Many natural distributions including language and, incidentally, gene expression often follow a distribution known as Zipf’s laws17 which states that a token’s frequency is the inverse of its rank. For language, this is generally fine, unless you are aiming to develop an LLM for a very esoteric task, however, in biology, it is often the lowest rank tokens that have the greatest meaning. For this reason, some gene tokenizers such as those in the Geneformer model have taken a normalizing approach to deprioritize high level housekeeping genes and up sample low level but differentiating genes18.
The primary function of a network, then is to adjust its inner parameters such that it can faithfully reproduce the statistical distribution of the training set. One of the key features is that different parts of the model can learn different inherent distributional features of the training data. In the limit, the statistical features that can be learned by the model are balanced by both the prevalence of those features in the training set and the capacity of the model to learn a sufficiently nuanced approximation of those features.
The impedance mismatch occurs when these criteria are not balanced - e.g., the inherent underlying structure of features in the training data are not matched to the knowledge modeling capacity of the network.
A few ways this can happen are the following
The training data is extensive, diverse, and well represented of the domain to be learned and is sufficiently large to present a full range of statistical distributions within it — from very specific to very general. But the model is too small to sufficient parameterize all the generality of the training data. This type of situation will result in difficulty training because the model only has the capacity to consume a fixed amount of information from the training data. Training for a longer period of time may result in instability if the model is too small as the model tries to adjust to varying statistical information piecewise. As the modeling capacity or training epochs increase, the training loss should smooth out as the overlap between different batches should be absorbable by the network capacity.
The statistical distribution of the training data is much smaller than the model capacity. This mismatch occurs if the training data is not distributionally complete (eg it is not sufficiently diverse or extensive) while the model has a much larger capacity. In this case, the model will be able to continually refine its precision simply by updating with finer and finer adjustments until it can nearly perfectly model the training data. If training is continued for an extended period of time, this result is overfitting or memorizing the training data to such a degree that performance is poor when deviating from that data on a test set. *Note: this idea of overfitting is along the same lines of why regularization techniques like weight decay and gradient clipping are used to improve training. Because of the exponential nature of the softmax function that is typically used at the end of a network, if any particular set of weights starts to increase, they may continue to increase ad infinitum if the only objective is to optimize a loss function. Weight decay and clipping provide a means to temper this — this is the mathematical version of the “paperclip optimizer” problem.
Both of these cases can be problematic for training performance. The transition from one domain to the other has been studied by Sutskever et. al. as the double descent problem19 — namely that when considering both data and model capacity, there are three domains of generalization performance. (Of note, this article was actually published before the widely cited Kaplan et. al.20 article on scaling laws)
The first where the model is too small for the data or training epochs, but nevertheless can learn some of the more salient features specific to the training data that are shared in the test data (e.g. both losses decrease)
The second where the model capacity passes through a “critical phase” where it can start to refine its specificity on the training data to the point of essentially memorizing its specific detail not shared in the test data — training loss decreases, test loss increases
The third where the model and training epochs are sufficiently matched such that the model has seen and can absorb sufficient distributional generality of the training data to apply to the test data.

Figure 2: Examples of the double descent observation across both model parameter size and training epochs indicting the optimal stopping epochs for any given model size21. The observation is that for any given training set size (left), as you start to scale up the model, in the near term the model learns features in the training set that are also shared in the test set. At this stage the model capacity is restricted so it can learn first order features. As the model passes through a critical region, it begins to learn the nuances of the training set in an increasingly memorized way — such that these nuances do not translate to the test set and generalization erodes. As the model continues to grow, the capacity of model can start to manage higher order abstractions in the training data that resume generality and the test set performance again begins to improve monotonically beyond that point.
Biological Data Sets and Model Size
So what is the intuition for the biological data sets that are intended to be used for the development of foundation models and the future of scaling laws in biology?
The intuitive approach to take is based on the distributional expectations of the underlying training data — this is based on the underlying idea of how connected datasets are and at how many layers of abstraction. The layers of abstraction, for example, could be simple -- for example, two genes that are co-expressed which may appear in nearly every data set, batch and epoch in the same proportion, or more abstract such as the relationship between a specific metabolite concentration and a genetic sequence variant which may only appear by virtue of several layers of abstraction and may never appear in a data set. We can take some solace in the expectation that biological systems do have inherent structure at different levels — this is what generally leads them to some form homeostasis (from which they might infrequently break out in the process of, for example, cell differentiation).
This inherent structure, for example in gene regulation at the transcriptomic level, may be the reason that models do not need to be all that large to begin to flatten out their loss functions, at least along a single dimension. Indeed, recent reviews have indicated that complex DNNs frequently perform similar to or even worse that more simple models like logistic regression on many tasks (see refs 7-9). The fact that losses on validation sets are still high, but not improving significantly with increasing training or model size indicates that the issue is more likely in the training data, not in the model architecture22, or at least the scale.
Incidentally, one of the more interesting observations in one of the reviews is that scGPT specifically performed better than simpler methods on a data set that was designed to be further out of distribution from the training data.
Among all the datasets, the pretrained model specifically excelled with the multiple sclerosis dataset, which was crafted by the scGPT authors to represent an “out of distribution” scenario: the fine-tuning training set consisted of neuronal cells from 9 healthy donors, and the test set consisted of neuronal cells from 12 multiple sclerosis patients23.
This does hint a bit at the broader generalization capacity of DNNs, however the bulk of the review articles on single cell genomics are definitely mixed on the current performance benefits vs simpler models.
The Natural Intuition is that Biological Data Sets Will Be the Limiting Factor
The evidence seems to indicate that the limiting factor in the ability to generalize lies principally in the scope of the underlying training data, not in the model scale or architecture. This would indicate that if we go about rapidly expanding the model capacity, we are more likely to end up in a situation of overfitting vs increasing generalization or “emergence”. This may not strictly be the case if the training domain is limited — for example if the limit is solely on sequence space, it may be the case that sequence space can be sufficiently comprehensive such that all layers of distributions are represented in the training data — more generally, sequence space lends itself more amenably to data augmentation techniques because of their one dimensional features. It’s not immediately obvious, however, that synthetic data will be useful for future training on tasks that are not uniquely sequence derived (for example, solubility). One could possibly supplement this with physics based calculations of these features on synthetically generated data.
On the Performance of Scale in Sequence Space
One specific instance of an attempt to demonstrate the scaling law for one dimensional sequence data in the protein domain is the xTrimoPGLM model which has been cited at 100B parameters and ~1T tokens — more in line with some of the large language models24.
To review the performance of this model against, for example, the ESM2 models, the authors report the following:
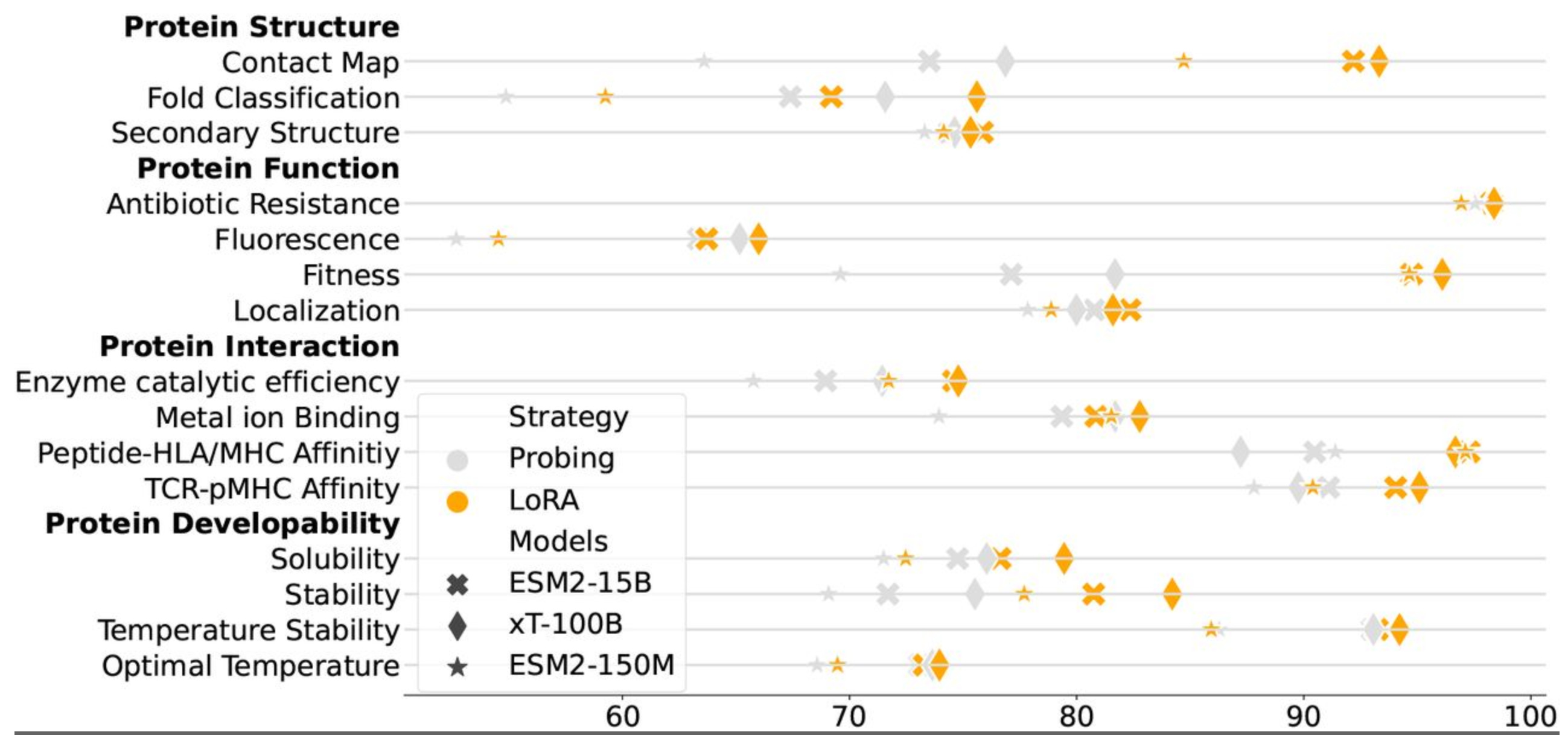
Figure 2: Comparison of protein modelling performance of ESM2 15B parameter model and the xT-100B parameter model showing that in some cases the larger model can perform better as reported (from the above ref).
This model was quite large by most biological model standards yet did not appear to significantly improve too many features. The authors argue that this model demonstrates “scaling law” performance, but like many SOTA comparisons, it is mixed. As of this writing, the code and weights for this model are not disclosed.
Further, it is not without mention that these statistics are difficult to interpret as the group reporting this data is also reporting SOTA results in nearly every category of model across every task in both proteins and genomic modelling, in most cases by marginal amounts. This is quite rare in most academic publications. When performance improvements are marginal and tasks may be internally defined, it is difficult to draw conclusions.

Figure 3: The Biomap SOTA leaderboard25.
And Multi-modality…
As models aim to incorporate more multi-modal data, despite the inherent structure, the distributional space expands super exponentially — not just in the dimensionality of any one space (for example, transcripts) but also in the combined dimensionality of multiple data types. As such, it’s likely that the main barrier will be in the training data and the scaling of model capacity is more likely to overfit than to generalize.
It is definitely worth noting that generative models for language and visuals (images/video) are so accurate currently and can be generated effectively ad infinitum that it doesn’t seem like we will ever run out of data for LLMs, however, this begs the deeper question about whether you can extract more data from a system by successive processing or whether those returns start to rapidly diminish. I’d expect the latter such that massively large models may have rapidly decreasing returns if real world data starts to be limiting (and if there is the ability to detect synthetic data such that it is not rehashed in new training sets)
In Practice, It’s Engineering
This discussion is just a set of ideas for thinking about scaling laws — and particularly as they might apply to the future of biological foundation models. At the end of the day, it is still an engineering question. As noted at the beginning, one of the most powerful features of deep learning models is that they can learn features that do not need to be human prescribed. It’s certain that there are patterns in biological data sets that we have no concept of and will continue to be unveiled with DNNs, however, the question of whether any given training set will be sufficiently representative of these generalities such that simply scaling a model will develop the capacity to model the nuance would be pretty unexpected.
At the moment, scale is almost certainly not all you need.
References:
https://www.tomshardware.com/news/startup-builds-supercomputer-with-22000-nvidias-h100-compute-gpus
https://dev.to/thenomadevel/googles-gemini-the-next-big-thing-in-ai-revolution-17a4
https://www.forbes.com/sites/kenrickcai/2023/08/25/evolutionaryscale-ai-biotech-startup-meta-researchers-funding/?sh=2ff9b1ec140c
https://www.theinformation.com/articles/thrive-capital-to-lead-purchase-of-openai-employee-shares-at-80-billion-plus-valuation
The Specter of Emergence and AGI

2+2 = fish 2+2 = -6 2+2 = 3 2+2 = 4 (EMERGENCE!) Much of the current media recently is filled with commentary of AGI and its potential impact on the world. Large political blocks and movements along with a cadre of AI companies are elevating the message that the specter of AGI may very well lead to the extinction of the human race. There is some sense of…
SOTA Seeking – A Knife Fight in a Phone Booth

One of the most memorable quotes I have heard in my time in commercial sales organizations operating in transformative and rapidly moving technologies is the following: “When you have a knife fight in a phone booth, everyone ends up getting cut” The sentiment is about how customers interpret differentiation that companies aim to position and how they pres…
https://www.biorxiv.org/content/10.1101/2023.10.16.561085v1
https://www.biorxiv.org/content/10.1101/2023.09.08.555192v1
https://www.biorxiv.org/content/10.1101/2023.10.19.563100v1
https://magicwandai.com/gpt-4-is-a-220-billion-parameter-8-way-mixture-model-george-hotz/
https://www.science.org/doi/10.1126/science.ade2574
https://www.biorxiv.org/content/10.1101/2023.07.05.547496v3.full
https://www.biorxiv.org/content/10.1101/2023.09.20.558508v1
https://www.biorxiv.org/content/10.1101/2023.05.29.542705v4
https://www.nature.com/articles/s41592-021-01252-x
https://endpts.com/atomwise-ceo-on-ai-in-biotech-shifting-focus-to-tyk2-drug-and-pipeline/
https://pubmed.ncbi.nlm.nih.gov/12633463/
https://www.nature.com/articles/s41586-023-06139-9
https://arxiv.org/abs/1912.02292
https://arxiv.org/abs/2001.08361
https://arxiv.org/abs/1912.02292
https://www.biorxiv.org/content/10.1101/2023.05.29.542705v4
https://www.biorxiv.org/content/10.1101/2023.10.19.563100v1
Image Ref: https://cdn-images-1.medium.com/v2/resize:fit:1600/1*m2gDBT_nc-iE7R4AM3sHBQ.jpeg
https://www.biorxiv.org/content/10.1101/2023.07.05.547496v3.full
https://www.biomap.com/sota/