
Building Automated Researchers
Superpowers for Scientists


Preamble and TLDR:
This Substack is about providing intuition in a semi-technical manner for readers at the intersection of biology and technology about what is becoming possible.
Developments in the capabilities of AI systems and, more importantly, what they are enabling are critical to understand. I have always been a proponent of knowledge management; indeed, I believe it is the most important near-term application of AI systems1 2. Over the years, I have read and annotated thousands of research publications and have become quite adept at doing so, however, it is hardly a scalable approach. Recently, LLMs and their extensions including RAG (retrieval augmented generation) systems have been built on top of many data sources, both public and private. Services like Perplexity.ai are aiming to raise hundreds of millions of dollars to compete in the massive market of internet search, and more focused entities like Elicit, Scispace, and OpenEvidence have been focused on more specific fields like scientific and medical research. The trend is moving toward an "answering" platform vs. a search functionality. This article is about this trend, but more importantly about the tools that are being developed to accelerate it. It is about the capability of automated software engineering, information accessibility, and co-pilots, and how they are fundamentally transforming what can be done and what problems can be tackled. It is an experiential description of how a non-career software engineer (me) can approach the creation of powerful AI products. It describes how to construct a RAG system on databases of hundreds of thousands of research publications, and how this was done from a consumer MacBook, in about two weeks, without a software engineering background. Software is among the most leverageable technologies we have ever invented -- it enables individuals to do amazing things. This article is designed to provide intuition for readers and perhaps some inspiration about what they might consider doing.
A Brief Outline of Contents:
There is a maxim that AI will not take your job, but a person who uses AI will. This seems obvious.
The hottest programming language is English -- Andrej Karpathy
Find more about me at: jasonsteiner.xyz
Introduction:
I have not meaningfully been engaged in programming since graduate school about 15 years ago. I have a working understanding of the principles of software engineering and in my younger years wrote graphics programs on my TI-82 calculator in high school and did moderate Matlab and C++ programming for basic neural networks in the early 2000s, but modern software development has not been my focus. I have, however, had a deep interest in knowledge management, NLP, and all things information. Doing anything meaningful in this space, however, seemed like a significant endeavor. Learning a whole new world of content, structure, systems, languages -- it was hard to know where to start on my own.
This landscape has dramatically changed.
ChatGPT prompt: I want to build a RAG system on a bunch of documents that are available on Amazon-- where do I start?
This is the simplest place to start. From here the process of investigating, asking questions, getting code drafted, error messages, debugging, etc. began almost seamlessly. There were indeed places where the current LLM systems got stuck and for these situations, more attention was required, but it was generally not deeply technical or domain knowledge that was needed, it was more just attention to logical detail. As the structure got built out, more bells and whistles were added, more edge cases were covered and better UI was developed, but it was almost all completely done with natural language prompts and expert facility with copy/paste. Currently, the system covers about 10% of BioRxiv, consists of a few hundred lines of decently clean code, and has functionality for relatively robust vector database management. This was done in about two weeks for a few hundred dollars in AWS bills (mostly making mistakes) and can be expanded to hundreds of thousands of research papers. There remains a lot of development that could be done. One of the most important lessons is understanding just how many knobs there are to turn when developing a product and how they affect the outcomes and performance. It's quite astounding and encouraging to know just how much can be improved.
Brief Interlude - why RAG?
There has been somewhat of a debate about the role of RAG in a world where the context length of LLMs is becoming massive -- millions of tokens from the new Gemini model. If you can hold millions of tokens in context, why would you need to retrieve information -- why not just include it in the context? I view this generally as a misunderstanding, and from practical experience, RAG will remain an important technology. From my experience, long contexts often lose context, and this has been published in several articles. For example, using ChatGPT for an extended period within the same thread eventually deteriorates the quality, utility, or correctness of the responses, this is particularly the case when writing code when at some length or follow-on question, the relevant context was dropped from the thread. This may be a prompting issue, but it seems to make sense that aiming to extract all of the highly relevant context from an extremely long window gets more difficult over time. Entering an entire database of content into a context window seems intuitively less precise than specifically searching for high-quality pieces of information to direct a prompt. This is separate from the potential cost issues associated with the computation of attention across millions of tokens, which seems wasteful. Currently, for example, ChatGPT seems rather wasteful of compute resources -- often regenerating entire code blocks to implement a single-line update. It may be the case that answers are cached in memory and not recomputed, but it certainly was not a great experience to wait for ChatGPT to say the same thing several times over when it could have simply output the specific edit requested. In an effort to be helpful, it got rather annoying.
The Basic Tools and Processes
This effort was built almost entirely on open-source tools, except the API calls to OpenAI for GPT-4o responses. This was mostly a cost consideration, but also a curiosity. The database that was used was BioRxiv because it is topically relevant and has all of the content deposited on AWS S3 openly accessible. The Current_Contents folder of BioRxiv goes back to 2019 and is about 5-6TB on disk.
Approaching this required a few steps, but they were all pretty straightforward. The most useful skill that was required was the ability to ask a good question to an LLM. For example, how do I set up an AWS account to get files? The answers to these questions will vary in quality and specificity, and for more tactical questions, I often preferred using Perplexity because it would cite the underlying sources that I could go to for details. This was significantly more useful than a Google search or chat forums. The technical details of approaching this project just a few years ago by aiming to read AWS documentation, decipher chat forum Q&A, perform various internet searches, etc. would have been significantly more challenging. The step function in tooling has been transformative.
It is difficult to overestimate how significantly a human language chat interface combined with RAG search and LLMs have improved accessibility to technical information.
The Basic Steps of a RAG
Get an AWS account set up with S3 and EC2 -- S3 is large/long-term storage and EC2 is their compute service. It's nice because you can choose how powerful you need a computer to be and just turn it on and off whenever you want — thank you cloud computing.
Ask the LLM to write a script to transfer files from the BioRxiv folder in S3 to your folder in S3. The transfer is relatively straight forward and ChatGPT provides a reasonably accurate code block to do so, but it does make mistakes so it's important to be aware of them. For example, ChatGPT will often say that BioRxiv is freely accessible, and this is true for the content, but it does cost money to transfer the files on AWS so the initial code may not include this and may fail. It is pretty effective to simply copy/paste an error message back into ChatGPT and it will likely give you an explanation and often updated code that will address the issue.
BioRxiv files are in a format called .meca which stands for Manuscript Exchange Common Approach -- these are zip files that include all the paper contents: a PDF of the paper, a corresponding xml, supplementary files, and original images. These can be unzipped into regular folders to see the files.
In the initial version of this RAG, text-only embeddings are generated. Image embeddings could also be done, but for simplicity, it was just text. It is relatively straightforward to ask an LLM for code that will extract text from .xml, PDF, .doc, and other file formats in the folders. For example, for .xml files, you can simply copy and paste the entire .xml file into ChatGPT and ask it to write code to extract the fields you are interested in. It gets this right about 90% of the time.
After all of the text is extracted, you need to break it up into chunks, or text fragments at smaller resolutions. There are several ways to do this such as Langchain tools like RescursiveCharacterTextSplitter. This is as simple as asking the LLM to write a Python script to take a text file and split it into chunks. For this project, the chunks were created manually after tokenization to be a specific token length for the embedding model. This keeps chunk size more consistent but may lose semantic boundaries. A character-level text splitter may keep better semantic boundaries but will result in variable chunk sizes after tokenization. If you can ensure the chunk size is within the embedding model’s parameters, this may be a better way to go, however, chunks that are larger or smaller will be truncated or padded, both of which lose some degree of semantic information. This is one of the many important tradeoffs.
After you've split all the text, you need to choose a model to create the embeddings for each chunk. There are several models to choose from and it's easy to ask an LLM which are good. An important point is you should choose a model that does the tokenization and embedding together so they match. Asking the LLM whether an approach they suggest matches the tokenization and embedding models ensures this is consistent. For this project, the embedding model was a 384-dimensional model from the SentenceTransformers library. This is a small model by commercial standards with more limited semantic representation capability.
In the process of extracting text and content from the XML, PDF, docs, etc., it's important to keep all the metadata attached and then you ask the LLM how to store all of the embedding, text chunks, and metadata in a vector database. A popular open source is Chromadb. Chromadb is by default in temporary memory so when you close the session, it's gone, but you can make a persistent file that stores it on the hard drive permanently. There are lots of nuances to how to use these databases, and open-source documentation isn't always very clear, so it took a bit of trial and error to learn what they were doing. Given that documentation wasn’t perfect, this was an area that the LLMs did not do perfectly in, and it took some troubleshooting. I suspect that open-source changes more quickly than can be incorporated into LLMs — which is another argument for good RAG systems.
After all of this, you have the whole BioRxiv text content stored and indexed as vector embeddings. You can set up a basic OpenAI API function to provide a prompt and when you enter the prompt before you send it to OpenAI, you create an embedding of the prompt and compare it to all of the embeddings in your vector database. If any of them are close, you can get that small text chunk and add it to your prompt to provide additional supporting information for the LLM. The LLM can then generate a response and you can then take each part of that response, create an embedding, and again compare it to your database to determine if any text chunks are similar or support that response sentence. These can be added as citations.
That's the basic setup for a RAG system. To go through each step, you can almost just ask the LLM how to do each part. The code and context that is generated is about 80-90% correct out of the box and you can converse with the LLM if you have follow-up questions. It's significantly more accessible than many might consider.
Dials and Decisions:
The details of actually building effective RAG systems are pretty extensive and can result in dramatically different performance metrics. For this project, I did not fully explore these variables but will discuss a few of the observations and key factors.
The gist of what a RAG is doing is trying to find small parts of content (or text) in a large corpus of data that are relevant to the prompt that you want to query. The basic key features are:
The size of the text chunk -- the smaller the size, the less context is available, but perhaps the more specific the information. For this project, I chose to first tokenize the text and then divide it into 256 token chunks. This was a practical approach to match the embedding input size of the model. The vast majority of chunks were 256 tokens and at roughly 4 characters per token were ~1000 characters. The distribution is below:

At the end of each document, there were smaller chunks if the text was not divisible by 256 tokens. There is also an unexpected short character peak of around 500 characters. This indicates that these chunks have a token size of likely 256 but are short on character count. Below, I’ll discuss some of the challenges with extracting and cleaning real-world technical data. In practice, these small length chunks are largely meaningless technical notations, which can be problematic.
The chunk size is important because it represents the semantic “unit” of the RAG. If it is too short, it does not capture enough detail and if it is too long it can be too diverse and, in the context of a RAG where chunks can be appended to prompts, can overwhelm the prompt embedding with extraneous information. This matching issue can be exacerbated with unusual chunk distributions like the above.
The way that RAG content is combined with a prompt to feed into an LLM. This is similar to point 1 about the size matching. For example, if you have a prompt that is 1000 characters, and you have a RAG database with text chunks of 1000 characters and you want to retrieve the top 5 matches to augment your prompt. The result will be 5,000 characters of RAG text and 1000 characters of the original prompt. If the RAG context is not well matched, this can drown out the role of the original prompt.
The dimension of the vector embedding itself is an important factor in the ability to capture semantic expression. In this project, an open-source embedding model was used that had 384 dimensions, which is on the low end. Embedding models that have 1000+ dimensions are more common in commercial applications. This makes the database larger to store, but also can make more specific matches to improve results.
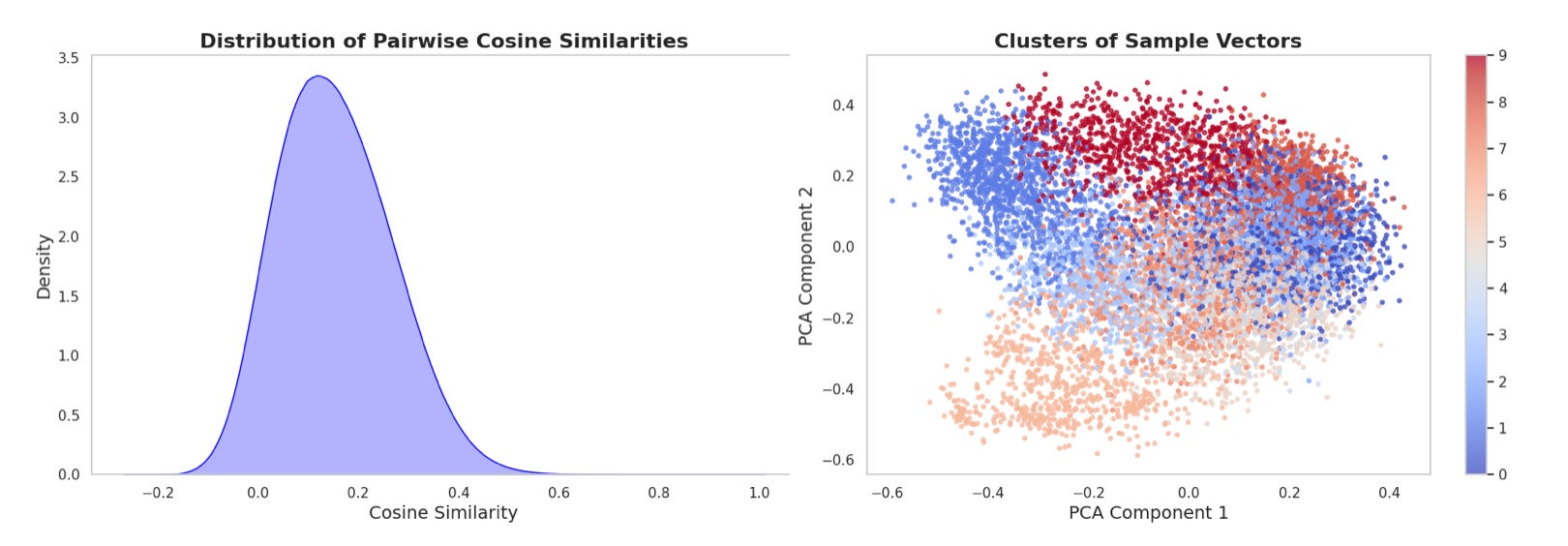
The thresholds for similarity. When searching for vector matches, the most common method is using a cosine similarity calculation. The threshold that is set for determining whether something is a high-quality match is a key factor. Often this is 0.5 or higher with higher values being more stringent. To provide some context for this, random embeddings from the database were correlated and resulted in the plot below (the PCA clusters were not assessed for shared topics but this is probably the case):

The average internal cosine similarity was 0.15. For various RAG and citation results, similarity thresholds were generally set >0.5 which would indicate a higher similarity. The similarity metric is very sensitive to the semantic content, and chunk length of the embeddings with respect to the sentence or prompt for comparison.
The way to add citations to a final result. A naive way to do this is to take the final results output and use a function that divides it into sentences and processes each sentence individually as a query. This works reasonably well if the LLM output is structured well, however, it's often the case that the output has formatting that doesn't consistently work well with sentence splitters, for example, if there are bullet points, and this results in sentence fragments which don't have good embedding represents and results in poor citation matches. Furthermore, this can also suffer from mismatched semantic sizes — for example, if sentence splitters produce relatively short sentences, their embeddings will not be well compared to the chunks in the database.

The above are some of the practical dials to turn with respect to the RAG mechanism, however, there are many others from an engineering perspective about how to make the overall system fast. In a naive fashion, the process described above works, but is not particularly performant. This is a significant area where companies can differentiate.
What Works and What Doesn't
It is worth reiterating that a significant fraction of the above worked pretty well out of the box by essentially conversing with an LLM. For the most part, the code that was generated could be copied/pasted and it would work. There were two key areas where this process broke down -- one in the code itself, and one in the data.
Mind the data:
It should go without saying that understanding the underlying data is of paramount importance. Real-world data, even if in a standardized format like BioRxiv can create significant issues on the edge cases. A few examples
The tools used to extract text from PDFs, docs, etc. had some dependencies on the formatting and contents of these documents. While this is often rather consistent, there are cases, where images and other formatting idiosyncrasies would result in broken embeddings. Error handling is important when processing tens of thousands of documents
A nontrivial amount of BioRxiv text is genomic sequences and other lists of supplementary data. These are viewed as text, but their embeddings are meaningless. When considering the discussion above about short prompt embeddings not being well represented, they would often return matches for these sequence embeddings, which had no semantic value and would distort a RAG prompt
It's important not to naively extract text from publication PDFs because they contain a significant text component consisting of references and materials and methods sections that are semantically not as valuable. This can generally be avoided by extracting the <body> text from the publication XML but is more difficult to avoid for supplemental information that does not have a corresponding xml.
Some of the examples that are encountered when directly extracting text from scientific publications, and particularly when using text extractors for PDFs or other document formats are below. XML text extraction is relatively clean because you can directly pull the text.
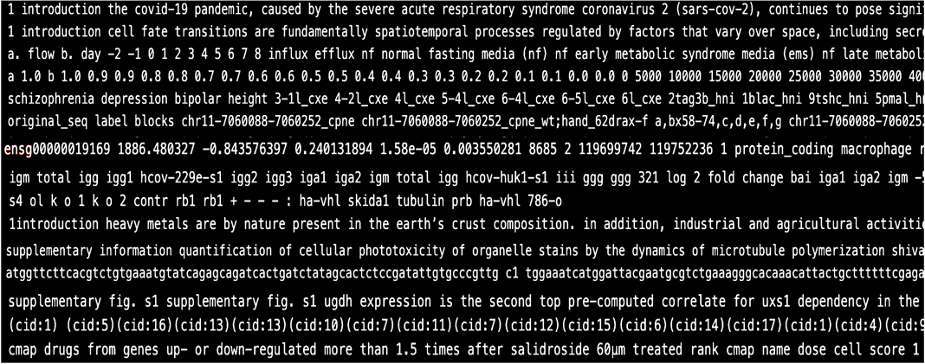
This type of text is difficult to clean yet is relatively abundant in technical literature. It can result in distorted embeddings.
For more details on the importance of real-world data cleaning — I would point the reader to an excellent article FineWeb: decanting the web for the finest text data at scale that has a robust analysis of data process for Internet content.

For the most part, LLM training is done on extracted text and these pipelines are designed to standardize it more than interpret it. This is likely a key distinction from cases where text needs to be extracted (e.g., is not directly available via HTML) such as in the case of technical content in PDFs and other formats.
When LLMs don't work:
There were several occasions when ChatGPT would get stuck in a pattern that it could not break from. Often this was when a piece of code did not work or work as expected and it would attempt to regenerate the code to address the issue but would not be successful after many attempts. A result of this, if one could not logically dissect the code, is that the solutions that were continually suggested became increasingly convoluted and difficult to follow and often proposed a range of new variables that needed to be tracked. It was possible to make suggestions to the LLM about what might be wrong in the code, and this sometimes broke the chain and got the LLM back on track, but this requires understanding the logic to suggest changes. In some cases, I used both ChatGPT and Perplexity and entered the outputs of one into the inputs of the other. I found that, in general, ChatGPT was better at writing code, and Perplexity was better at debugging it. It was an interesting observation because both are based on the same LLM on the back end but have different product interfaces on the front end. The room for product differentiation is very high. I found that LLM debugging is reasonably robust in terms of suggesting debugging print statements and so on. Rather impressive.
It’s worth pointing out that throughout most of this I primarily used ChatGPT and Perplexity, however, I suspect that several other LLMs will be comparable and that there will be significant room for products to be differentiated specifically for coding.
What ended up taking the most time:
In all of this work, the most time spent as a novice was spent on relatively trivial issues, such as keeping track of variable types, correct syntax in addressing indices, and formatting/data processing issues. Developing an understanding of what functions and libraries did in terms of variable types, was a significant time consideration -- and the formatting nuances of {} or () or [] or indexing of lists, dicts, list of dicts, dicts of dicts, tuples, lists of tuples of dicts, etc. as well as ensuring that formatting processing for text was consistent and accurate was time-consuming.
Cleaning Up
A strikingly favorable capability of LLMs was the ability to clean up and format code. The process of copying/pasting/editing etc. code blocks was not particularly well structured. I suspect that a more experienced developer would set out with a better overall plan and architecture, but as an exploration, this was not the approach. Nevertheless, once a code block was working, the entire block could be entered into an LLM asking it to clean up, clarify the functions, clearly demarcate variables, clean up library imports, keep comments for consistency, etc. and it would do so. This was exceptionally useful.
The End Results
Below is a screenshot of one of the outputs of the system. As discussed above, it was important to make the prompt sufficiently rich that it could find reasonable RAG matches. Nevertheless, the matches were still relatively limited. It may very well be the case that since this was only on 2024 data, there may not have been good matches in this technical dataset.
The citations section is reasonable but would require more work to make precise. On a single EC2 instance, this returned as presented in a few seconds over a vector database of ~1.4M embeddings across ~23k publications. Commercial RAG products use different methods to deliver results such as combining websearch and are not necessarily strictly vector searches as this was.

Automated Software Engineering
Companies and products like Codium and Devin have created quite a stir in the software engineering world for the promise of the ability to create an automated software engineer. Based on my experience, I could see this being possible to a degree, but it remains to be seen how far the complexity can be pushed. My experience of asking a question, getting a code block, copying/pasting, getting an error, copying back into the LLM, and iterating was surprisingly successful. The experience also, of passing the outputs of one LLM into another was also surprisingly productive. It is easy to see how these agents can be built. However, occasions where a basic logical breakdown occurred that required me to line-by-line assess the code and provide suggestions were also not uncommon. These issues were less related to the technical accuracy of the code than the intended performance -- for example, the code would run, but it would not have the precisely desired behavior and appeared incapable of identifying the logical inconsistency without prompting.
It is, however, very obvious this will be a core part of the future.
The Most Important Thing
The most important thing is what these capabilities represent and enable. Just a few years ago, this would have been a significantly intractable challenge. I would have considered it would require substantial independent learning of a strong technical foundation that would be rather time-consuming. Now, however, it is doable in very rapid fashion, and more importantly, I have been able to learn along the way.
The idea of LLMs as co-pilots, tutors, etc., is extraordinary for anyone who wants to learn or build new things. There remains significant headspace to develop exceptional products and I don't expect that AI tools will consume all professional work, but they will substantially lift the base across the board.
The impact of this type of acceleration will be pretty extraordinary. What YouTube, MOOCs, and others have done for self-education; AI tools will do tenfold.
Making Things Easier
There are now a host of available tools that make all of this quite a bit easier. Most of the AI companies have released tools for this purpose - a recent example includes a host of tools from Cohere and services like Pinecone that make RAG and vector database management quite a bit simpler. Recently Claude 3.5 Sonnet was released which many say has strong coding capabilities. The purpose of this post, however, is to perhaps inspire others who do not come from a traditional software background about what is actually achievable now, that was not before. In my experience, it’s been rather extraordinary.
If you like this content, please consider subscribing and sharing with the buttons above.
For more about me, you can find me at: jasonsteiner.xyz
SQL to GQL - On the Future of Biomedical Search

Preamble — This post is a more detailed dive into the role of graphs in biomedicine and search in general which was outlined in a previous article on drug repurposing using AI. The topic of graph machine learning for relational data prediction has rich technical detail which cannot be covered sufficiently in a brief article. Graphs are a more generali…
Drug Repurposing Using AI

Preamble: This post originally appeared on the Timmerman Report linked here and, being for a more general audience, is less technical than other posts on this Substack. However, it’s a very interesting and important trend nonetheless. One of the most powerful aspects of deep representation learning is the ability to express an arbitrary set of feature…