


Part 2 - CRISPR, AI, And the Future of Medicine
Converging Disciplines For a Perfect Pairing

NOTE: This is Part 2 of the Genomic Medicines and AI article that follows the details of the genomic dissection of HbF regulation for sickle cell disease (SCD) and the future of genomics and machine learning. Part 1 is here
Genomic Strategies for SCD
The tools developed from the ENCODE project and advances in genomic technologies have led to a number of ways to approach the treatment of SCD and various approaches have been taken. For a comprehensive review, the update by Zarghamian et. al.1 gives a good summary.
There are pros and cons to different approaches, but the mechanism of CASGEVY is one that showcases the potential flexibility and power of genomic medicines because of its indirect and potentially tunable mechanism of action.
As an aside, one of the very interesting applications of genomic medicines is the ability to fine tune a specific regulatory circuitry to an arbitrary degree. It is often the case that we do not know the mechanisms of action of drugs, or they may have many off target effects. The ability to precisely tune a regulatory region of DNA provides for a direct translation between the target (e.g., DNA sequence) and the mechanism of action (e.g., DNA editing) of a therapeutic.
To jump to the end about the strategy taken and compress several decades of genomic tool development in a single paper, I would refer the reader to the following paper2. In short, this paper describes the dissection of a specific region of DNA in the BCL11A gene that reduces the expression of BCL11A in a fine tuned manner. The result of this, as described above, is a shift toward HbF production which has a desired therapeutic effect to treat SCD.

The understanding of the regulation of the hemoglobin locus (beta and gamma globin) has gone through several stages of technological evolution. For some of the earlier work on understanding the beta globin locus control that maps to some of the early ENCODE dataset timelines (for the interested reader) I’d refer to Palstra et. al.3 which reviews some of the early work in mapping the long range DNA interactions underlying the regulatory circuitry.
To briefly review the circuity analysis of the expression control of BCL11A and its impact on HbF from Canver et. al., the below images break it down:
Level 1: The first level is understanding what the available regions of DNA are in blood cells (where hemoglobin is made) — these open regions are a proxy for understanding where it might be possible for regulatory proteins to bind to DNA. These are called DNAse HyperSensitive regions or DHSs. Assays for “open DNA (aka chromatin) have been around for a long time and produce images like the below (all images from or adapted from Canver et. al.). The image shows the BCL11A locus and various markers of what parts of the gene may be available for regulatory protein binding along with a reference for the genomic variants (rs1427407 and rs7606173) that have been discovered from GWAS to be associated with high HbF. This is the initial map for what regions might control BCL11A expression. Combining this with GWAS data that show which variants are associated with higher HbF expression points to which regions may be important.


Level 2: The resolution of these plots is not good enough for genetic engineering. When CRISPR was developed, it allowed a much finer grain resolution dissection of each of these regions as below — the graph is showing how CRISPR disruption of each of the three subregions (the 3 DHSs —+55 +58 and +62 — see Level 1 image for where these are) is affecting the HbF expression (e.g., tuning the regulatory network to various degrees)

Level 3: To make this even higher resolution, the authors created a model of the impact of each individual nucleotide on the possible expression of the desired hemoglobin and produced images along the lines of the following (a finer resolution of one example region DHS +55 — see Level 2 x-axis for reference)

With this type of analysis, the authors were able to model the impact of every single base of DNA on the expression of a gene of interest. This above plot quite literally shows how every base in a target region would either increase or decrease the expression of the desired gene — at a base by base level — through perturbations of the regulatory machinery of the globin gene. Green downregulates HbF (increases BCL11A), red upregulates HbF (decreases BCL11A). This level of granularity is extraordinary and enables a fine tuning that has not been possible before and it is fully generalizable.
The net result of all of this intensive molecular biology work and tool development over the decades since ENCODE and the Human Genome Project is that it might be possible to understand the impact of every base of DNA on the expression of a gene — and this might be a way to tune our genetic circuits.
For CASGEVY, the final target mechanism looks like the following4. where the specific genetic target was tuned to be located within a region of the BCL11A gene whose alteration would reduce the binding of an expression enhancer of BCL11A, reducing expression of BCL11A, therefore increasing expression of the desired hemoglobin (HbF).

This has been an incredible story from incredibly hard won experimental data and tool development.
The point is — this is not a typical drug — it is not a small molecule, it is not a protein, it does not even target the therapeutic protein (hemoglobin) in any direct manner (for example correcting the mutation).
This is a therapy that targets a “dark” part of our genome, in a resolution at the level of a single base, that tunes the expression of a regulatory protein that further tunes the ultimate gene expression of the protein of interest (HbF)
As the saying goes - let that sink in…
The Intuition for the Future
The intuition of this is important and worth highlighting for the reader. The vast majority of diseases are very complex — they are networks of interacting elements and most (if not all) are ultimately governed by our genetic context. As an aside, it’s critical to note that our genetic context is not just the sequence of DNA, but the entire regulatory mechanism around it, including epigenetics and all of the downstream consequences. But what this story of CASGEVY points to is that there is a way to genetically tune our biology — not a binary 1 or 0, but a continuous gradient of impact.
This genetic therapy is the culmination of decades of tool development to dissect the semantics of gene expression and regulation.
With advances in genomic technologies, data sets and deep learning, combined with a growing array of genome editing tools, we will increasingly be able to model these therapies in silico and rapidly translate then into real world medicines
The Deep Learning Revolution in Genomics
One of the most significant features of deep learning is that it compounds over time. There is no other tool in the life sciences that does this. We say that we stand on the shoulders of giants, but historically we have done so in a linear way. We can now do so in an exponential way. What this means is that the history of tool development to generate data will be encapsulated in increasingly sophisticated models of biological systems. In its own right this would be extraordinary, but when paired with tools like CRISPR, it is revolutionary. There is some serendipity that the deep learning and genetic engineering revolution were initiated in the same year5.
The impact of this is starting to be seen in the development of foundational models of genomics and cell biology. Combined with the rapid development of genetic engineering technologies, we have set the beginnings of exponential development.
Take, for example, publications such as the Enformer6 model published in 2021 (or its more recent update Borzoi7 or BigRNA8 from Deep Genomics). All of these models can produce similar predictions of the impact of genetic variations on a whole host of different possible readouts.
The Enformer authors have produced data sets that have predicted the gene expression impact of every single SNP in the 1000 Genomes project and similar approaches like AlphaMissense have provided predictions for the potential pathogenic effects of every possible genomic variant (albeit only in protein coding regions)9.
These models have been built on top of the data generated from massive efforts like ENCODE and provide a level of resolution into the genomic circuitry that has never before been possible.
If one were to combine them with gene regulatory network (GRN) models like any of a host of transcriptomic deep learning models or datasets, one might be able to connect genetic variation to complete gene regulatory networks in-silico.

And indeed, some of the leading AI-forward pharmaceutical companies like GSK are doing just that11.

The critical aspect of these models is that such analysis can be done in-silico — without the need for time intensive and costly wet lab experimentation. At the very minimum they can prioritize wet lab experiments — certainly hypotheses will need validation.
As the data increases, and the models improve, what used to be two decades of genomic tool development will be compressed into increasingly efficient moments of compute.
Indeed, we are well on our way toward this end with increasingly high performance predictive models integrating datasets that have been generated over the last two decades, from GWAS, CRISPR, and neural networks.
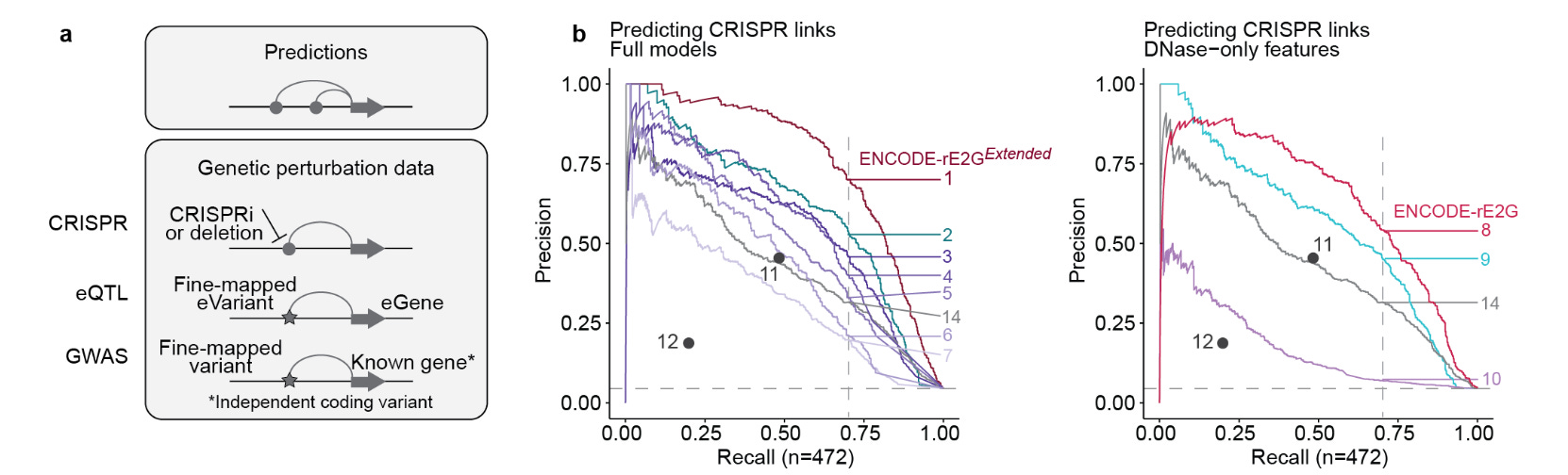
Figure: A recent publication of predictive models of gene-regulatory components trained on data from the ENCODE12 project showing the ability to do in-silico predictions similar to those that underpinned the development of CASGEVY.
There is little doubt that biological networks and regulation are complex, and there is little estimation that, at least near term, machine learning will deliver specific answers to complex diseases, however, what we can see is that the tools that have enabled the dissection of the hemoglobin locus and resulted in the first ever precision genetic engineering-based therapy, can be moved increasingly in silico to address more complex regulatory networks in high quality experimental contexts.
Combined with the parallel developments in genetic engineering tools, I see a world where we can understand and begin to tackle every genetically driven disease in an increasingly rapid and profound manner
Concluding Thoughts
The story of genomics, CRISPR, and deep learning are converging. At the core of each is the essence of information, data, and engineering. The more we know, the more we can model, the better we can engineer and, ultimately, the more we can begin to address the complexities of human disease.
It’s an extraordinary time to be alive.
References
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9868311/
https://www.nature.com/articles/nature15521
https://pubmed.ncbi.nlm.nih.gov/18282504/
https://www.nejm.org/doi/full/10.1056/NEJMoa2031054
https://www.rand.org/randeurope/research/projects/ai-at-the-helm-of-a-species-evolution.html
https://www.nature.com/articles/s41592-021-01252-x
https://www.biorxiv.org/content/10.1101/2023.08.30.555582v1
https://www.biorxiv.org/content/10.1101/2023.09.20.558508v1
https://www.nature.com/articles/s41576-023-00668-9
https://www.nature.com/articles/d41586-023-01504-0
https://www.biorxiv.org/content/10.1101/2023.07.26.550634v1
https://www.biorxiv.org/content/10.1101/2023.11.09.563812v1