


“It is not the strongest or the most intelligent who will survive but those who can best manage change.”
- not Darwin
Brief Aside: This Substack has recently gained a number of new subscribers. If you are new here and are interested in a concise summary of the chronology of this Substack over the last 2 years, this link is a good place to start.

Disclaimer: The article below is considerably more speculative and forward looking than the usual tempered tone. The rationale is that 1) the content is new and 2) it is an area that I expect will have dramatic consequences that are not currently appreciated or understood well.
Contents:
References (also in-line)
The Origins of Life
One theory about the origins of life is that it all began with RNA. One of the most flexibly diverse molecules for both its ability to encode information and be chemically reactive, the thesis is that ribozymes (enzymatically active RNAs) were the seed of all biological systems today. These molecules could both transmit information, catalyze their own replication, and evolve a wide range of other chemical properties. Over time, there was a shift to more stable information management in the form of DNA and more robust enzymatic and structural properties through proteins, but RNA has retained a broad diversity of use cases far above and beyond an informational intermediary. Evolution at all levels, whether it be chemical, biological, ecological, or sociological, is the origin of the sophistication of the world around us.
It is a force of nature. That force is being brought to machines.
The implications of evolutionary and recursively self-improving software are not well understood. There is a chorus of mixed commentary about the impact of AI in the coming years. This Substack has generally focused on “low-frequency” signals — those that will underpin dramatic transitions in technology and society (more on the frequency paradigm can be read here below).

The low-frequency signal this article will discuss is the implementation of evolution and recursive self-improvement in software and computing. Early reports, for example, from the AlphaEvolve team at Google, estimate practical leverage of these approaches at 0.7% of Google’s computing budget (~$85B in 2025). Models from both OpenAI and Google have progressed from the GSM8K benchmark to gold medals at the IMO in less than 2 years.
This article is intended to describe some of the techniques that are being developed in both reasoning and evolutionary development of AI systems to provide an intuition for how far these methods will be able to go and what the world may look like as they develop.
Recursive Self-Improvement
One of the major goals of AI labs has been to automate AI research. This is one of the triggers of what some call the “fast takeoff” model of AGI, where acceleration of progress becomes recursive. Automating any form of research involves two main components:
Hypothesis generation, knowledge synthesis, and reasoning
Experimentation
Both of these domains are active areas of research for recursive self-improvement. The first domain currently has a primary focus on LLM-based reinforcement learning for reasoning improvement. The second domain, at least in the case of AI research, is primarily rooted in software code and currently has a focus on evolutionary methods.
Reasoning
If you’ve ever used one of the “reasoning models” like Gemini Pro, o3, or even Perplexity, you’ve probably seen the pop-up “thinking” boxes that show a process that the model is going through to answer a query. This type of approach to building models is distinct from the “scaling” approach that the earlier LLMs were based on. These earlier models were essentially monolithic neural networks that were trained on massive corpora of data and, in a sense, retained that knowledge in their weights. They operate in a single response type format, generating responses token by token autoregressively, for example, question → answer. Pre-trained models had a base set of weights that could then be fine-tuned in a variety of ways, for example, with input/output pairs or techniques like reinforcement learning with human feedback. It’s important to distinguish these approaches:
Fine-tuning on input/output pairs updates the probabilities of token generation by example. A base model will have probabilities that are learned from a general corpus, and then, when provided a specific set of supervised examples that may have slightly different probabilities in a specific context, will calculate a loss function that will back-propagate to update the weights.
Reinforcement learning takes a different approach by training a network that represents a policy that aims to maximize the reward of a given input/output pair. In the context of human feedback, the reward is the human preference for a specific response over another. The policy network aims to modify the base models’ probabilities to produce outputs that maximize the reward (often the preference function).
Reasoning models take these approaches further, and there are several technical challenges with long-horizon reasoning training. Firstly, human feedback or online (real-time) reasoning training samples are very difficult to acquire in practice, so most reasoning examples are taken from static training sets (also called offline training). These long-horizon reasoning models can be thought of as a continuous stream of tokens. These token streams can be broken down into discrete thoughts, but in practice, since tokens are fed autoregressively back into the model, it may just as well be a single stream. This stream of tokens represents a discrete reasoning trace and can include back-tracking, restarting, and so forth.
A reasoning “trace” is just the progress of thoughts: thought 1 → thought 2 → thought 3 → … answer. Traces are often not linear in logic, and can be more akin to a tree structure, however, from an LLM perspective they are a continuous stream of tokens.
Given that “reasoning” can be thought of as just a single stream of tokens, the outstanding challenge is how to make that stream coherent over long traces. A naive approach is to just use supervised fine-tuning on “correct” and “incorrect” traces, perhaps incorporating a contrastive method. However, this approach is both brittle and perhaps not that fruitful, as there is no particular reason that the probabilities of tokens in a reasoning trace will differ dramatically from a pretrained base model.
A more productive approach is to use reinforcement learning that learns policies around specific chains of tokens that are both successful and unsuccessful reasoning threads. One way that this has been done effectively is described in this paper:

A basic breakdown of the approach is as follows:
A base LLM will have a predefined probability for each token generated in a trace.
In a version of reinforcement learning called Q-learning, the goal is to learn what is called the Q function. This is the function that maps all future expected rewards to a specific state and a specific action: Q ( s, a ). In the context of language, the state is the input string, and the action is the choice of the next token. When choosing the next token, it is assumed that the action will be taken that results in the highest Q (or cumulative future reward) value.
For completeness: Q is a measure of the total expected future rewards of taking a specific action in a specific state under a specific policy. Typically this policy is to choose the action that results in the high Q value. This can be applied to each step in a chain. Formally it is:
\(Q(s_t, a_t) = r_t + \gamma \cdot \max_{a_{t+1}} Q(s_{t+1}, a_{t+1}) \)where t represents each time step, s and a represent the states and actions available at each step, r represents the current reward and γ is a discount factor.
In the context of correct reasoning traces that are coherently consistent and result in correct logic and a correct result, the reward calculations are straightforward. The reward of the last token is 1 for correct or 0 for incorrect. This reward then gets propagated backwards to the penultimate token (which assumes that the future token will choose the highest reward and so the Q value of the n-2 string state under action of the n-1 token is calculated (there is also a future step discount applied as a hyper-parameter, but that is a detail).
In short, this process can be calculated backwards from the end of a successful reasoning trace or an unsuccessful one.
The model then considers these Q values for each token (or each state) as the probabilities of that state and action (or next token) and calculates the loss function as the difference between those probabilities and the base probability of the pretrained model. This updates the model’s weights to produce tokens that are probabilistically more likely to result in successful reasoning traces.
The net effect of this approach is a hybrid of supervised fine-tuning where the loss function is calculated as the difference between the base model token probabilities (conditioned on the prior sequence) and the Q value of that token, as back-calculated from the success of the reasoning trace.
I suspect (purely speculation) that this is similar to the approach that OpenAI used for their IMO model for a few reasons. In this interview1, the authors mention a few notable things:
The approach they used was put together over just a few months — this technique was published in November 2024, which would have put it in the correct time frame as a novel approach to develop early 2025.
There is a strong emphasis on the generality and natural language component of the approach. They did not use formal verifiers like Lean to check the proof.
There is a strong emphasis on “hard to verify” tasks, which this reasoning approach would be amenable to. The approach does not have any formal verification steps, which may be useful additions for tasks like theorem proving.
The authors also made considerable concessions about the distance between this type of reasoning model for competition math and research math. This comment is consistent with the fact that these models still do need examples of verifiable outcomes to learn from, and it is not clear that they will be able to generate accurate reasoning traces for cases not in their training set.
While impressive, these models are still next-token predictors — just ones trained to learn policies that guide which tokens are most likely to lead to coherent reasoning traces. It is quite possible that these learned policies may, in fact, produce novel reasoning threads just from probability, but there is still no underlying (or at least interpretable) logic model that is underpinning that generation.
Moreover, it still remains that value attributions need to be assigned to the endpoints of the reasoning traces. This remains straightforward in domains where “correctness” is clear, but still less so in undefined domains such as research or creative endeavors.
I think we should expect these models to continue to be exceptionally impressive at mimicking coherent reasoning. There is reason to believe that either learned policies or fine-tuned base models might be able to generate long sequence of coherent reasoning logic even when applied to novel circumstances.
Evolution
At its core, evolution is a process of mutation and recombination in the context of a fitness function. In biological systems, each step of evolution is more or less random (this is not strictly the case, as variants do have preferences), and the fitness function is reproduction. There isn’t really a sense of a learned “policy” to guide the individual steps of natural evolution; rather, the filter of survival/reproduction creates the policy by trimming the suboptimal branches. In software, the process is similar.
Software evolution can happen on a few different levels:
The string-level — code can just be serialized into a string or continuous variable that is the subject of mutation
The module-level — code can be formulated as an abstract syntax tree with subtree recombination
The ensemble-level — recombining at the program level
There are several important considerations when developing evolutionary code systems. The code needs to be syntactically correct at the string level, structurally correct at the module level, and logically correct at the ensemble level. There also needs to be two main resources: an evaluator and a resource pool. A good example of this is the diagram below from the AlphaEvolve team at Google:
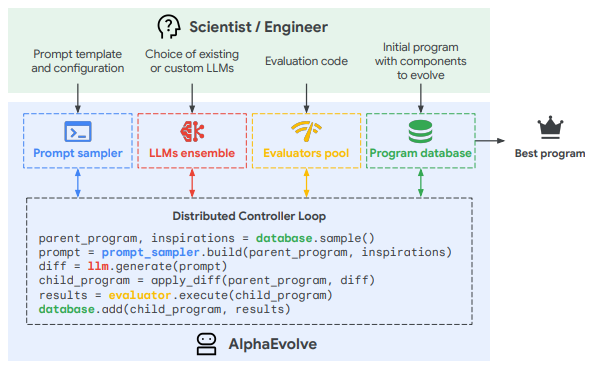
LLMs form the foundation of code evolution, but the most important aspect of the framework is how the LLMs are used. From the image above, consider the following:
The program database contains LLM-generated code snippets with metadata. The metadata may include, for example, specific tasks the code executes and how it performs. This is the evolutionary “pool” of materials and is maintained in a statistical balance of explore/exploit scope for variation.
The prompt sampler generates detailed prompts for the LLMs that include the current code to evolve, selected code snippets from the program database, context like code performance, metadata, objectives, and other information that frames what type of variation should be affected.
The LLM ensemble is a mixture of LLMs that perform different parts of the code updating. This may be purely token-level generation, or there may be higher-order code recombination.
Evaluators run code and determine how it performs. The data is then stored in the program database and fed into the next iteration along with other code variants from the database that might be effective recombination partners or examples of mutational variation.
This process is relatively straightforward — the power lies in the ability of LLMs to generate effective code variants based on objectives, metadata, and a pool of code samples.
A similar approach was taken in the recently published paper from Sakana.ai

which had a somewhat more defined architecture that evolved specific functionality for code generation agents that were benchmarked against SWE Bench. The approach started with a single agent and, through iterations, was able to update and evolve its own functionality for discrete components such as prompts, file structure, context management, specific code editing tools, retry logic, etc. Evolved agents were able to view their own logs and were evaluated on standard coding benchmarks. An example of agent evolution and performance improvements is seen below:
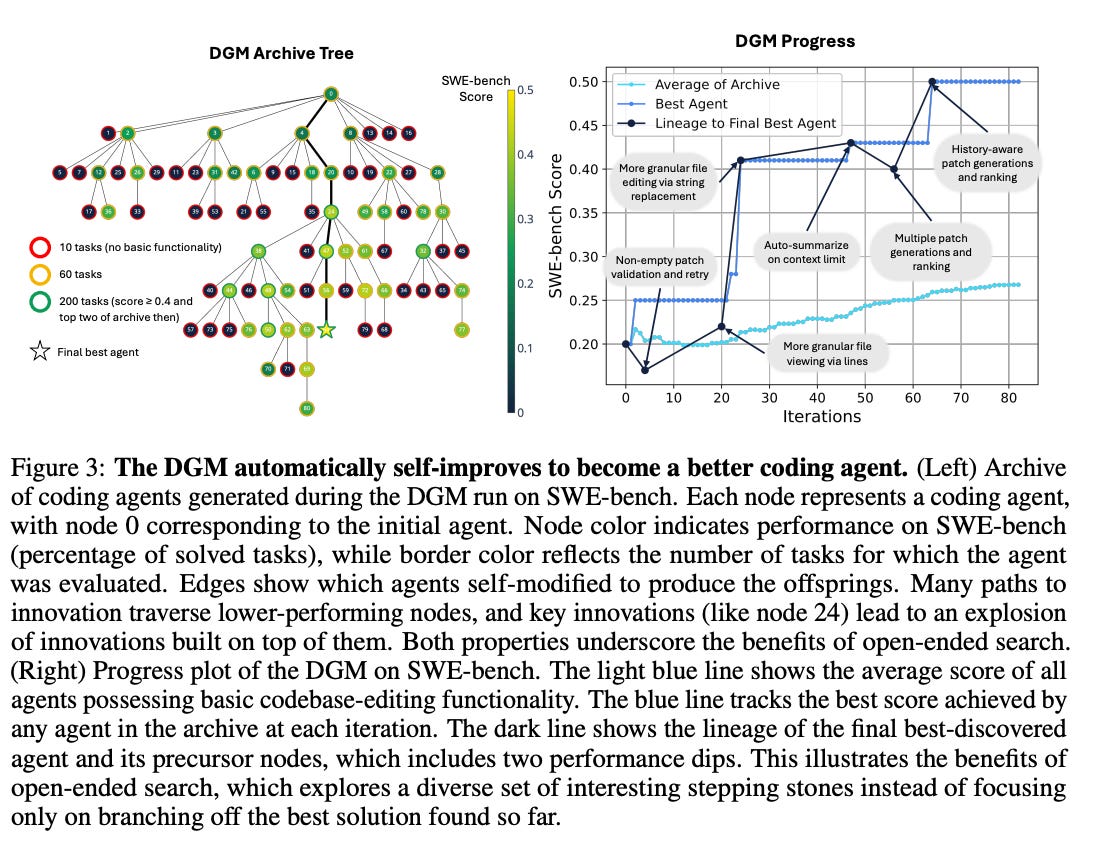
What makes these evolutionary approaches particularly significant is not just their technical sophistication, but their generalizability. Unlike reasoning models that excel in domains with clear correctness criteria, evolutionary systems can optimize for a diverse range of measurable objectives — efficiency, creativity, robustness, or entirely novel metrics we haven't yet conceived. This flexibility suggests we're witnessing the early stages of a more fundamental transition in how software systems develop and improve.
Implications and Conclusions
Reasoning and coding are at the core of a great deal of our world — not just in software, but in design, manufacturing, security, commerce, finance, etc. It seems quite evident that we are early in this trajectory of recursively self-improving AI, but that there is not a specific barrier to its progress (save perhaps energy consumption). From a practical perspective, the acceleration of these capabilities will accrue to the companies that have the resources to leverage them to their fullest potential. It is a feature of the AI (perhaps more broadly computational) world that resource scale is a necessary (but not sufficient) criteria to realize the potential of an idea. Such is the nature of algorithms.
A common critique of LLMs is that they will always suffer from stochastic hallucination. While this remains a challenge, it may not be a fundamental barrier. Any system of inference — whether symbolic or statistical — is subject to limitations, including "unknown unknowns." Gödel’s Incompleteness Theorem famously shows that any sufficiently expressive formal logical systems cannot be both complete and consistent, and while LLMs are not formal systems, they have similar features: an axiom logic (albeit fuzzy) and irreducible gaps in coverage and coherence.
Yet, techniques like ensemble learning — especially across models trained on different data or architectures — have been successful in reducing error rates and improving groundedness2.
Recent approaches such as adversarial training, prompt refinement, and LLMs acting as judges or verifiers have made progress in mitigating hallucinations, though these solutions are partial and domain-dependent. Rather than expecting perfect reliability, it may be more pragmatic to manage and minimize failure rates to levels acceptable for specific applications
The rate of progress is unlikely to slow down. It will become normalized in daily life for most people (it already has been surprisingly so), but what will be happening behind the scenes is the evolution of machines.
Machines are no longer just executing logic — they are learning how to generate it. Recursive self-improvement, whether through reasoning models trained on long-horizon Q-values or evolutionary agents refining their own tools, signals a structural shift in software: from static execution to dynamic adaptation. This transition parallels the biological arc from chemical autocatalysis to neural complexity — only this time, it’s happening orders of magnitude faster, with fewer physical constraints.
What emerges from this process may not think like us, but it will adapt. And in systems where adaptation outpaces comprehension, managing change — not mastering complexity — becomes the defining survival skill.
Evolution, once the domain of biology, is now a computational substrate. The machine is learning to evolve.
References (also in-line)
https://arxiv.org/pdf/2402.06782