


Anatomy of an AI Scientist
What They Actually Do and Look Like

TLDR: This article describes the inner workings of AI scientific agents. It goes into code examples of some of the leading agents currently released and describes how they are constructed. The objective, as with the theme of this Substack, is to provide a closer intuition for what these tools look like for people who may not be as close to their development or implementation.

for more see jasonsteiner.xyz
Introduction
This is the year of the AI Agent. The tech world is ablaze with applications, vendors, and demos -- all aiming to streamline tasks using AI. Companies and individuals alike are wondering how agents will transform the world.
This is an article about those agents -- specifically scientific agents; however, it has general concepts that can apply to other use cases.
The objective of this article is to break down the parts and describe how agents are assembled from the bottom up. In practice, agents are not particularly complex to understand. They can be, however, complicated to implement. The central aspect of an agent can be thought of as a logic flow -- something you might write in a Standard Operating Procedure (SOP) for a job function; however, a substantial part of the implementation lies in the error handling and detail management. This is a direct consequence of the inherent stochasticity of the underlying LLMs that are used to produce the outputs that govern the steps that will be taken next. In reading through the implementation code of multiple scientific agents, it struck me how much of the code was dedicated to ensuring that edge case errors did not derail the entire process.
Contents:
This article is structured in a few parts with a concluding wrap-up:
The topics will discuss the concepts below:
Architecture and Roles - This is an overview of the different types of roles and functions that an agent has. An agent "role" can be considered as essentially an LLM prompt that is designed for a specific purpose. The prompt may serve the purpose of generating ideas, evaluating ideas, drafting code, or any number of other functions, but the "role" is still just a text prompt that is provided to an LLM
Environment, Actions, and Tools - This is an overview of the world that the agent has access to. For example, an "environment" for a scientific agent can include a list of Python libraries that it can use to write code, a list of databases and their standard APIs that can be accessed, and/or the running context of the agent’s history as captured in memory (which can be both persistent or episodic). The Actions may include things such as "search for more information", "summarize progress to date", "evaluate relevance", or “write a Python method”. Tools may include specific deterministic functions or code like a function that performs PCA or other statistical analysis. Tools may also include template code blocks that be used as reference code for an LLM to update for a specific use case. For example, there may be a template code for performing a database query that can be customized for a specific query as generated dynamically by an LLM
Planning and Reasoning - This is an overview of how agents are initialized, in the sense that when a task is started, how does the agent determine what tools, roles, and actions may be required to complete the task and then establish a workflow to begin executing? Strong "reasoning" LLMs can provide significant benefits here but are not strictly necessary
State, Reward, and Training - This is an overview of how to train agents. This is generally done in a reinforcement learning format where the overall agent has a "state" and is given "rewards" based on actions that it takes. The section will also cover how memory is tracked (which is generally just using a simple dictionary). The "state" of an agent needs to be defined numerically such as a vector -- to do this requires the ability to numerically score the current attributes of the agent which can be done deterministically (using code) or can be done using other LLMs as evaluators. For example, an evaluator LLM can be used to determine the relevance of the current summary of a research agent’s observations to the initial prompt. This evaluation could return a numerical assessment that would then be part of the "state" dictionary of the agent at that point in time. For training general models, it is important that the state not be directly tied to the specific details of the training data. For example, you would not use text embeddings of a specific research task as a part of "state" because the embeddings will vary from sample to sample. "State" should be the result of an assessment that can be universally understood independent of the specifics of the sample. Rewards are generally separate from "state" and can be calculated as some general metric tracking progress -- such as how many tasks have been completed in the original plan according to the quality of the progress definitions. Defining both the state and reward components is the most important part of building a model that can benefit from reinforcement learning
Agent Narrative Description
AI Agents are an architecture challenge, however, unlike traditional software, they do not have deterministic workflow wiring. The most intuitive way to think about an agent is to think about a group project. Imagine you are sitting in a room with a collection of colleagues and your task is to investigate a scientific topic and come up with a research plan and results. For today's agents, you'd consider the task to be entirely digital (meaning everything can be done on a computer), but in the near future, it will be possible also to control robots and run real-world physical experiments. To break down the tasks you’d want to consider the steps and skills needed for the team to perform the task. The roles may include:
A researcher to gather information and summarize it
The assessor to determine how relevant the information is to the current task
The analyst who runs technical analysis and reports back on the results
The project manager who keeps track of overall progress
etc...
There may be other roles that you'd want to include but this a starting point. The second thing that you would want to specify is the environment that the team works in. Components of this environment can include things like:
The programming tools available such as Python libraries
Tools like APIs for various services like searching the web or gathering data from a specific resource
Examples of specific programming code for analysis or deterministic calculations. This code can be fixed or just a template that can be dynamically generated
Possibly other aspects like environment variables for passwords, cost limiters, or other constraints that might be given
The range and type of "tools" in this case is very open ended and additional tools can be added.
The third part of the agent architecture, which may also be considered part of the team roles, is a set of specific roles and methods that are solely dedicated to ensuring that the other roles are producing correct and quality output. I am specifically identifying these roles as separate because a great deal of code is dedicated to this purpose and these roles are not strictly related to the intellectual logic flow of an agent.
One of the most important observations about these agentic architectures is that they are still entirely dependent on the stochastic outputs of LLMs. Despite the fact that LLMs are getting very good, and there are various tricks to strongly indicate that the LLM should produce a specific output in a specific format, this is not a guaranteed event when the process is automated. In some cases, this can be managed by Python libraries like pydantic for type matching, however, when the expected outputs of LLMs may include more complex content, it is not uncommon that these type checking functions would include things like regex searches for specific language in the output or even other LLM prompts that are looking for specific items in the output.
One important example of this output assessment is the capturing of error outputs from code that runs. One challenge, in this case, is that error traces from code outputs can be very long, and it may be desirable to find the specific causal error in the trace to introduce back into the LLM workflow to make the necessary corrections to the code.
The idea of context management is very important for agents and also relates to agent memory which is the fourth major pillar of effective agents. Memory can be both long-term (persistent) and short-term (context based). Persistent memory is important, for example, in enterprise deployments because it retains a long-term history of the agent's actions. Short-term memory is important because LLMs have a fixed context window that may limit the amount of information that can be passed from step to step. It is very important for agents to have access to this memory for each step both for context and so that it does not duplicate steps, but this requires effective management of output context to ensure that the context added to short-term memory is relevant and not superfluous, Short-term memory is generally just stored as a dictionary that is passed from step to step whereas long-term memory is typically written to a database like Postgres.

Figure: The overall components of an AI agent’s code can be thought of in these main categories. I’m specifically splitting out “auditor code” as separate from the Roles because it is a core component of ensuring that the agent executive autonomously but is not a core part of the “agentic” functions. It does, however, occupy a substantial amount of the code base.
Thinking of an AI agent as a team of experts with the above key attributes and tools is a useful framework. However, a major feature of these teams is that they can be trained to do their research better. The way this is done with agents is through a reinforcement learning paradigm. The classic way of thinking about reinforcement learning is the grid world environment. This "environment" is essentially a 2D grid like a maze, where there are rewards and punishments on various squares. The agent starts on square 1 and can move in any permitted direction. When they move, they collect rewards or punishments along their path, and the goal is to learn the best decision making policy for getting to the goal with the most reward. Each time the agent moves, it has a different state which consists of its grid location and cumulative reward.
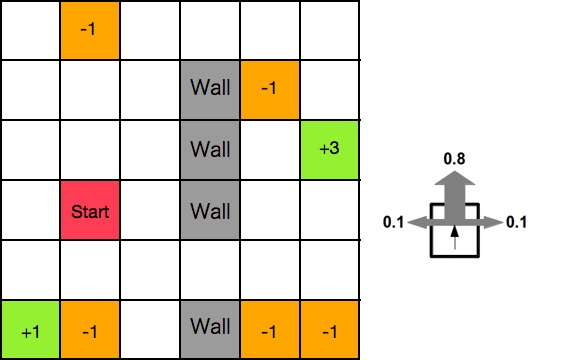
Figure1: This is a canonical example of “grid-world” for reinforcement learning training. There is an agent that starts on the red square and has a policy of how to move in the grid (up, down, left, right, and not through walls). A goal might be, for example, to collect maximum rewards in the minimum number of steps. The naive “policy” of the agent will assign probabilities of moving in each direction based on the square that the agent is on. As the agent moves around, the probabilities get updated as the rewards collected accrue. A learned policy will assign a high probability to moving in specific directions based on any given square that maximize collected rewards.
The analogy for more complex AI agents is the same. There needs to be a defined state and there needs to be a defined reward and these need to be assessed at each step of the process. There are three concepts to consider here:
The state
The reward
The action space
Going back to the analogy of a team tackling a research project. In order to make the agentic framework generalizable, it's important to define the state in an evaluative sense -- meaning the state should not include the specifics of the task but should be an evaluation of it. This can be done through a scoring system using another LLM prompt, for example, for content relevance or any other feature of interest. The action space of the agent can be defined as the things that it can do -- for example gathering more information, performing an analysis, querying a database, etc. At the outset, the action space as a function of the state is naive -- it is not clear which action is the best to take at the given state, so an action is selected probabilistically, and after that action is taken a new state is calculated. In parallel to action selection with respect to state is a determination of the reward function. A simple way of thinking about reward for an agent is the number of tasks that have been successfully completed at any time. Note that this requires an LLM role that assesses whether a task has been adequately completed or not based on the current state (remember the current state is generally just a Python dictionary of all the actions and outputs). The reward might then return a value that says X number of tasks have been completed in the plan. The objective of this set up is to learn over many iterations which actions as a function of which states will lead to the highest rewards. (Note that rewards can be both positive and negative, for example, taking any step might be an incremental negative reward which would also push the agent to minimize the step taken)
Implementation Details and Examples
Below are several examples of technical details of agent implementations from various code bases.
Role Prompts
Prompts can be very detailed and lengthy depending on the role. The below code is taken from the “idea generator” role from Sakana.ai’s AI Scientist v223

*sakana ai-scientist v2
This prompt is designed to generate new research ideas using a tool which is the Semantic Scholar API. This tool is provided to the prompt in the variable {tool_descriptions}. The Semantic Scholar tool looks like this (partial view)…
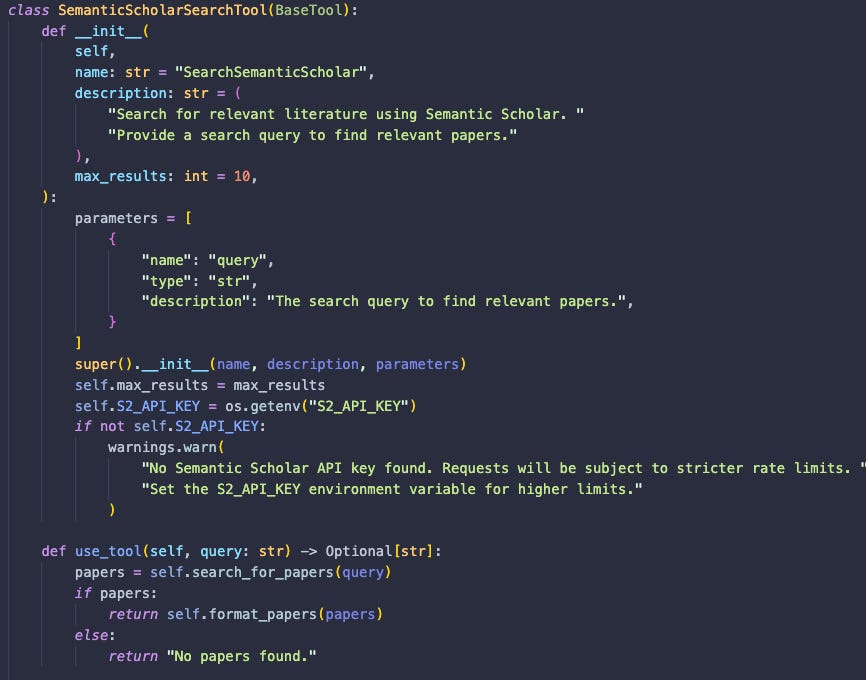
*sakana ai-scientist v2
…and has features that define its name, description, and a set of methods for using it. In the agent prompt, {tool_name_str} is a variable that composes the various names of tools that can be used by that specific role and adds these to the ACTION space for that role.
This agent is being instructed to return an IDEA in a JSON format. This is indicated by the text ```JSON``` and the provided structure. This is a strong indicator to the LLM that it should return this explicit JSON format but is not a strict enforcement. This prompting format is used because not all LLMs have a structured JSON output format. Prompts like this often have very clear language that indicates that the format must be EXPLICITLY followed because it will be used for automated parsing.
In describing agents as “LLMs in a loop”, this prompt, for example, shows that this role is iterated in a loop as seen below…
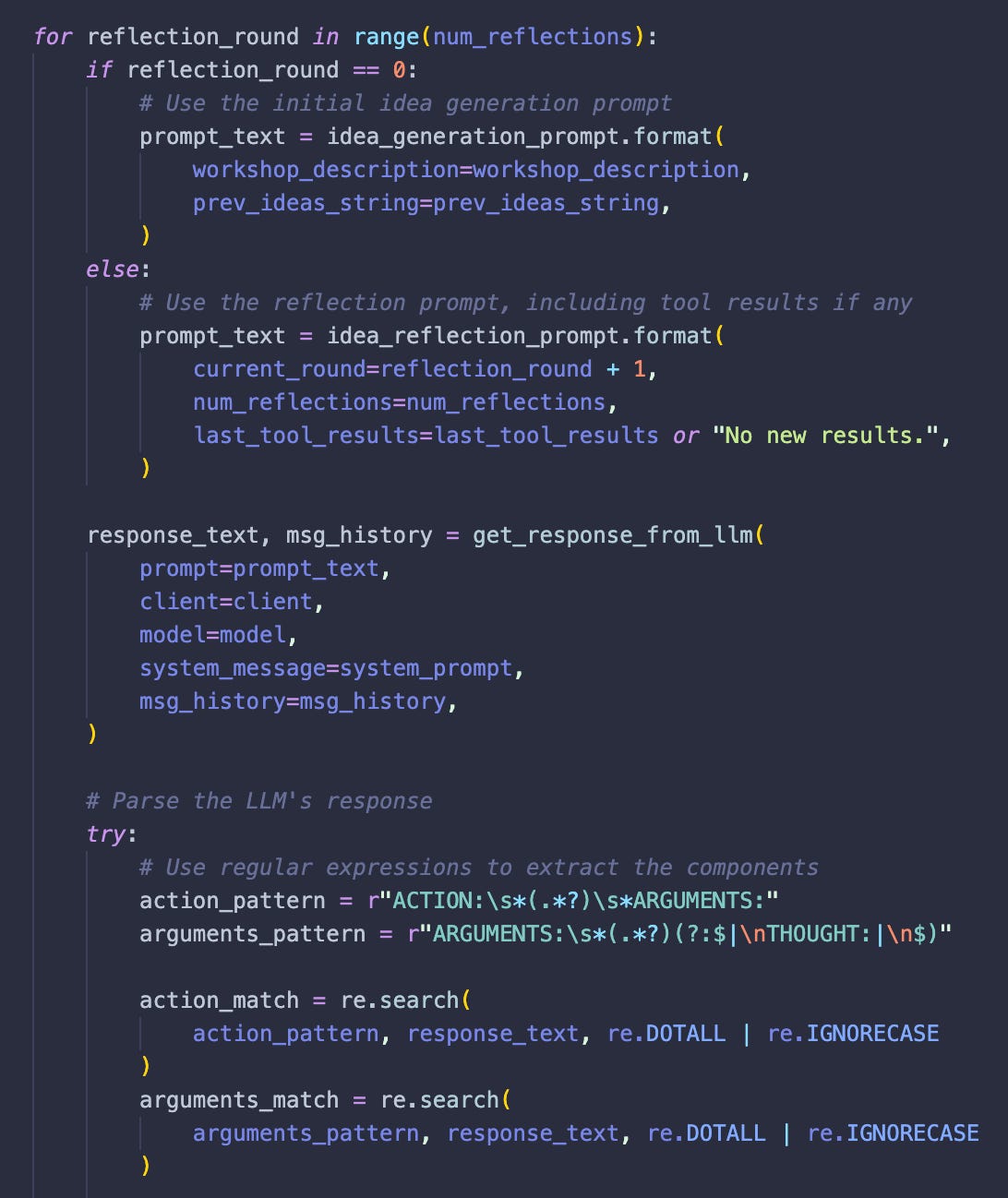
*sakana ai-scientist v2
…where previous ideas are encapsulated in a variable {prev_idea_str} so that the role can iterate multiple times. Note the regex extraction patterns for specific content returned by the LLM. When composing prompts that may return complex responses, it is common to both direct the LLM to return a specific format and to book end the desired content with special characters (or perhaps CAPITAL letters) so that it can be identified and extracted using regex patterns. In this code above, the LLM responses are parsed by identifying specific patterns bracketed by terms “ACTION”, “ARGUMENTS”,
”THOUGHT”, etc.
This is just one implementation of roles in an agentic framework. The idea here is that the prompts receive various inputs from the agent’s context and state and aim to provide structured outputs which are then stored as variables to be passed to other prompts.
Code Templates, Writing, and Running
An important tool for agents is the ability to write and run code. Code blocks can be used for anything that the agent needs to do deterministically. For example, below is a code block from the CodeScientist Agent from AI245 for creating and storing memories which are stored in a simple Python dictionary:

*AI2 CodeScientist
These code blocks can be stored in a folder and can be added arbitrarily to expand the capabilities of the agent. The ability to add new tools to an agentic framework is one of the most interesting features of these systems. In order to monitor this expansion of the toolkit, the CodeScientist approach, for example, has a method (using an LLM) that reviews this folder and produces a narrative output of the use cases of each code block which is stored as a reference JSON file like this:

*AI2 CodeScientist
This file can be used as input for a particular prompt that has a particular set of tools it can access to provide the context for what those tools do and what is required in the Python environment to install to use the code blocks.
It is also possible that LLM outputs can be used to generate specific queries that are passed to code blocks, for example, for SQL database queries or even that codeblocks can be written on the fly and stored as temporary .py files in the tools folder.
An important tool is one to actually run the Python code and capture the outputs and errors. This is done for both installing necessary packages and running code. An example of what this looks like for installing packages is below where the run method is a shell script that installs packages in the terminal:

*AI2 CodeScientist
This creates a new subprocess that checks if a package is installed and captures the outputs and errors of running the processes in stdout and stderr. Capturing the variables for the outputs and errors in this fashion can be used for any code that is run to ensure that the code is executed successfully. Methods that parse, for example, the standard error outputs for specific text like missing packages in an environment can be used iterated until the code is executed correctly. The key idea is that the logic of looping through the tools required, their dependencies, creating a subprocess to install those dependencies to make sure they are correct, and also running .py files while capturing both outputs and errors can be run autonomously until they are successfully completed. Ensuring that these steps are completed is a core part of the agentic framework.
Initialization, Evaluations, Training
At the outset, most agents start by defining the process that will be executed and the tools that they will need. This is one area where a strong reasoning model that can output a multistep process can be leveraged. This can be a very comprehensive process. For example, in the CodeScientist by AI2, the initial planning role has a very lengthy prompt that includes all of the tools, methods, and resource environment available and produces idea outputs that look like this (truncated):

*AI2 CodeScientist
This type of structured output is a research idea generator that proposes a research project, the range of things to consider for that project and the tools and resources that are expected to be needed to complete that project, for example, stored in the dictionary {research_idea_required_code_and _resources}. The tool descriptions are used as seen in the previous code to map to tool requirements and ensure that the necessary environment is installed to use them.
Training an agent requires defining the state, action, and rewards. In implementation, the “state” is often referred to as the “observation” at any given time. The rating of the alignment of actual states with predicted states is also conducted with an LLM providing a matching score. An example of what this looks like in the CodeScientist is below:

*AI2 CodeScientist
There are many steps in this specific code block, but the key things to note are the methods and the usage of LLMs to provide the confidence scores for the changes in each property of the observations based on an action. Properties of observations can be defined as, for example, specific task completion, various scoring metrics of output quality, or other defined features of the “state” observation of the agent. Using LLMs to look at observation history and make a prediction about the future observation based on an action provides a framework for a model to learn to predict the impact of given actions based on given states which is central to training the agent to take higher quality actions in any given state.
These are just some of the snippets of the code used to build and train agents. The objective is to provide visual intuition for how complex agents work internally, the centrality of LLMs in all aspects of the process, how data flows within an agentic framework, how code is incorporated and executed autonomously, and how agents can be trained to make better action decisions based on state progression and rewards. Conceptually agents are straight forward to understand but can be very complicated to implement well.
The Devil is Always in the Details
There is a vast space for agents to be developed and deployed — it will be as diverse as the teams and companies that will use them. The utility of agents will also range significantly and the devil is always in the details. The quality of agents will depend extensively on the quality of the data they have access to, the quality of the internal logic, and the quality of the underlying language models that drive them. All of these will be critical.
Perhaps even more important is the quality of the user experience. Especially for complex agents in the sciences or other specialized disciplines, the interaction of human expertise with agentic workflows will be essential for both the quality and credibility of the outputs.
It is a very exciting time for AI Agents, and I expect a blossoming field of new tools, capabilities and discoveries to come from them.
for more see jasonsteiner.xyz
References and Further Reading
This article references heavily from two publicly available open sources from AI2 and Sakana.ai for their respective agents. Specific code blocks come from the identified GitHub repositories as accessed on or around the date of this article’s posting. These are the most comprehensive codebases currently available for complex agentic architectures, though there is a substantial amount written about agents in general.
https://slazebni.cs.illinois.edu/fall15/assignment4.html
https://github.com/SakanaAI/AI-Scientist-v2/tree/main
https://sakana.ai/ai-scientist-first-publication/
https://allenai.org/blog/codescientist
https://github.com/allenai/codescientist
Love the “team of experts” analogy, and the honesty about how much work goes into just keeping these things from going off the rails.
Also, I created a quick video summary from it, hope you like :) It even includes the code snippets, which can directly be copied from the video: https://app.symvol.io/videos/anatomy-of-an-ai-scientist-1b3a
Jason, nice overview here of AI agents and this new class of "AI Scientists" that seem to be evolving very quickly in their sophistication. I was surprised looking at the AI2 Scientist and how lengthy and specific the planning prompt was. It makes total sense, and it encourages me to clean up my own agents to improve the formatting (and interpretation) of the code by the agentic tools.
I'm actually interested in hearing your take on an agent system I developed, so I'll email you, but this article was very helpful with the 2 very informative reference Scientists